多年来,计算机科学和工程界的人们一直在努力做各种优化。鉴于我们生活在一个资源有限的世界,人类一直致力于优化成本和提高速度。
在软件工程中,我认为,最流行的性能改进方法是缓存。虽然缓存有各种应用,但在软件工程领域,缓存背后的想法非常简单:把经常 需要/使用 的数据存储快速的 结构/存储 中,以至于可以非常快速地获取到。
事实上,缓存必须在两个方面更速:
- 确保尽可能多的文件请求可以获取(缓存命中),而不是通过网络或主存(缓存未命中)
- 使用它的开销应该很小:测试元素是否存在并决定何时替换一个文件应该尽可能快。
在本文中,我们将重点介绍第二部分:使用特定的方法实现 最少使用(Least Frequently Used – LFU) 缓存,使其元素测试和驱逐算法具有良好的性能。此外,我们还将介绍基础知识并探索这种缓存方案的用途。
基本介绍
LFU 是一种缓存算法,只要达到缓存的容量限制,就会删除缓存中的最不常用元素。这意味着对于缓存中的每个项目,我们必须跟踪它的使用频率。一旦超出容量的容量,将运行驱逐算法,移除最不常使用的内容。
如果您曾经实现过 LFU 缓存,那么您可能已经使用过最小堆这个数据结构,因为它以对数时间复杂度处理插入,删除和更新。在本文中,我们将介绍另一种实现它的方法。
但在我们开始之前,让我们先看看 LFU 在哪些情况下比其他算法更好。
LFU 闪耀的地方
假设在 CDN 上有一个资源缓存(在 CDN 上资源根据使用模式进行缓存)。因此,当一个用户请求的网页中请求一些图像时,CDN 会将其这些图像资源添加到其缓存中,以便其他用户更快地获得。
例如这个图像(资源)是网站的 logo,你能想象 Google 所有产品一天请求多少次它的 logo?我真的很想知道这个数字,但就目前而言,我们可能只知道这个数字是巨大的。
这种资源缓存是 LFU 缓存的完美用例。LFU 缓存驱逐算法永远不会驱逐频繁访问的资源。事实上,在这样的缓存中,Google 的 logo 几乎将永远被缓存。相比之下,Reddit,Slashdot 和 Hackernews 这些网站,如果由于首页上的新产品的新着陆页面而导致某些图像被访问,一旦超级风暴过去,资源将很快被驱逐,因为访问频率将急剧下降,尽管在过去几天他们被访问过很多次。
正如您可能已经注意到的那样,如果缓存对象的访问模式不经常改变的话,这种缓存驱逐的方法非常有效。LRU 缓存驱逐最近无访问的资源时,而 LFU 驱逐在风暴结束后驱逐不再需要的资源。
实现一个 LFU 缓存
现在,让我们深入了解它。正如我们之前所说的,我们不用最小堆作为 LFU 缓存的数据结构,而是采用更好的算法。
实际上,在 2010 年,一组研究人员 Ketan Shah 教授,Anirban Mitra 和 Dhruv Matani 发表了一篇题为“用于实现 LFU 缓存驱逐方案的 O(1) 算法”的论文(你可以在这里找到这篇论文),在这篇文章中他们解释这个所有操作运行时复杂度都为 O(1) 的 LFU 缓存的实现,包括插入,访问和删除(驱逐)。
在这里,我将向您展示如何实现此缓存并引导您完成实现。
数据结构
放心,它绝对不是像红黑树这样的怪物。实际上,它就是两个双向链表和一个哈希表。仅此而已。
为了理解这个 LFU 实现的基本原理,让我们将以图示的方式展示链表和哈希表。在这之前,我们先了解下如何使用哈希表和链接列表。
哈希表将使用通过由哈希算法得到的键来存储对象(在这里,我们尽量简单),值就是实际的对象:

链表就有点复杂了。第一个链表是“频率列表”,它保存所有资源的访问频率。此链表中的每个节点都有一个对象列表,该列表包含相同访问频率的所有对象。此外,对象列表中的每个对象都会指向其在频率列表中的祖先:
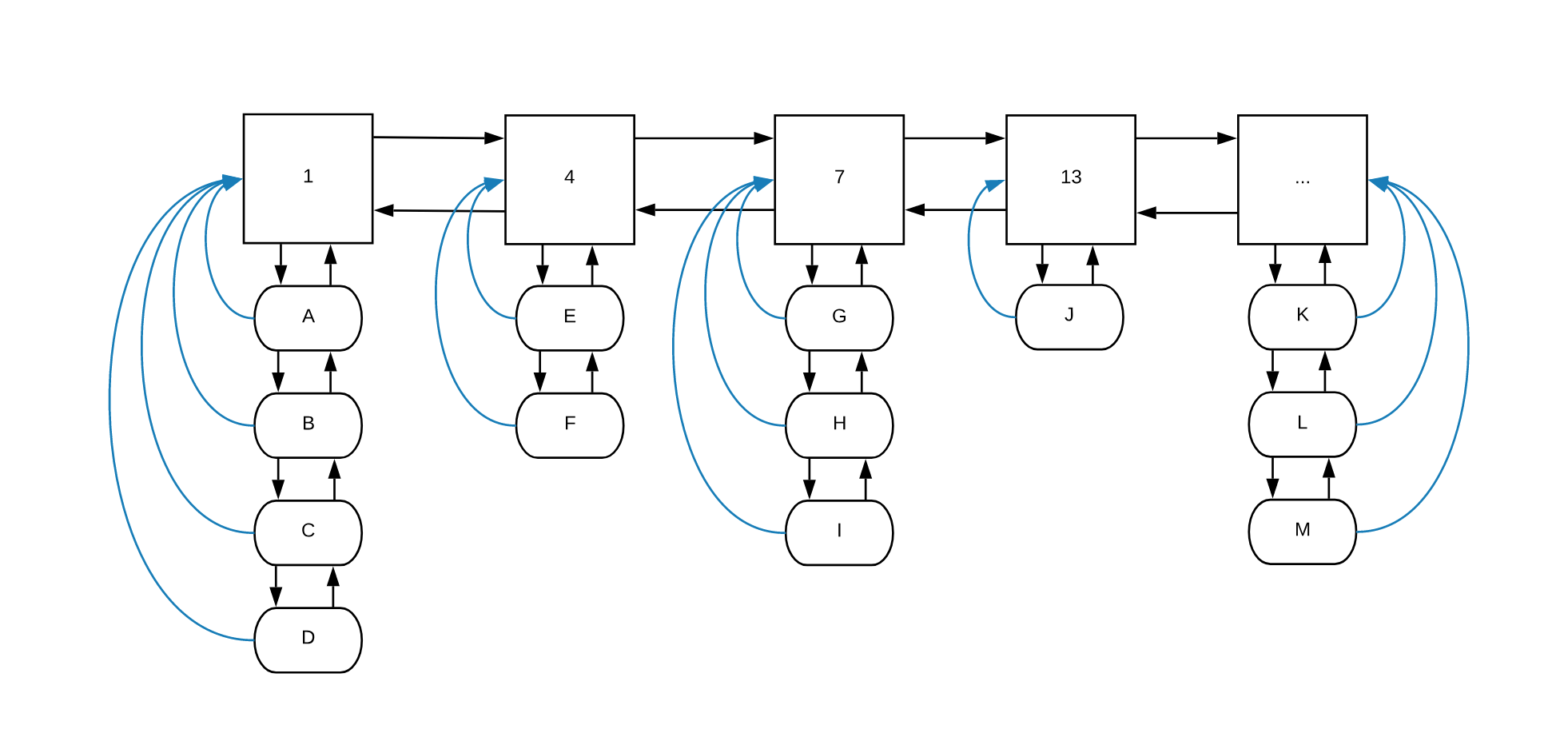
如果我们看上面的图例,可以注意到对象 A,B,C 和 D 被访问过一次。E 和 F 被访问 4 次,依此类推。蓝线是对象列表中的每个项目都指向其频率列表中的祖先的指针。
那么,如果再次访问对象 E 会怎样呢?以下步骤:
- 从哈希表中检索对象很容易(且容易扩展,
O(1)) - 我们要访问对象的
frequencyParent指针,看看下一个频率节点是否在链表中 - 如果在(例如
8),我们将对象插入为频率节点8下的第一项 - 如果不存在,我们将创建频率节点
8并把E添加到这个对象列表
检索对象并更新对象的频率是 O(1) 的。在我们开始实现算法之前,让我们首先建立我们需要的类型。
类型
正如我们之前所说,我们需要对所需的类型进行建模,这些类型将成为我们缓存的主干。
第一个 struct 是 CacheItem。它用来存储缓存中的实际对象:
type CacheItem struct {
key string // Key of entry
value interface{} // Value of item
frequencyParent *list.Element // Pointer to parent in cacheList
}
它包含可以用来在哈希表中查找的 key,要缓存的对象 以及 频率列表中指针的frequencyParent 指针。
第二个 struct 是 FrequencyItem,表示频率链表中的每一项。它包含一组 CacheItem 指针。我们将使用一个 map 当作集合来存储它,确保每个条目都是唯一的:
type FrequencyItem struct {
entries map[*CacheItem]byte // Set of entries
freq int // Access frequency
}
最后一个 struct 就是 Cache 本身了:
type Cache struct {
bykey map[string]*CacheItem // Hashmap containing *CacheItems for O(1) access
freqs *list.List // Linked list of frequencies
capacity int // Max number of items
size int // Current size of cache
}
Cache 包含 哈希表 bykey(命名来自上面链接的论文),频率链表 freqs,缓存的最大容量 capacity,以及 当前已缓存的数量 size。
New, set 以及 get
让我们看看让这个缓存工作所需的前三个函数。第一个是一个构造函数:
func New() *Cache {
cache := new(Cache)
cache.bykey = make(map[string]*CacheItem)
cache.freqs = list.New()
cache.size = 0
cache.capacity = 100
return &c
}
构造函数 New 会创建一个新的 Cache 结构,并为它设置默认值。这里您可能想知道 list.New() 是如何工作的:对于频率链表表,我们将使用 Go 的 container/list 包,这是个整洁的链表实现。您可以查看其文档以获取更多详细信息。
第二个函数是在 Cache 上实现的 Set 方法:
func (cache *Cache) Set(key string, value interface{}) {
if item, ok := cache.bykey[key]; ok {
item.value = value
// Increment item access frequency here
} else {
item := new(CacheItem)
item.key = key
item.value = value
cache.bykey[key] = item
cache.size++
// Eviction, if needed
// Increment item access frequency
}
}
该函数需要 2 个参数: key 和实际要缓存的对象 value。然后,它检查对象是否已经被缓存。如果已经被缓存,只会更新对象的值。否则,它将创建一个新的 CacheItem,用来封装实际的对象,设置完 key 和 value,它将把这一项添加到 bykey 哈希表中,并增加缓存的 size。
最后在两个逻辑分支中,我为缺失的部分添加了一些注释:
- 必须知道如何增加某个
CacheItem的访问频率,但我们还没有实现它; - 如果
size达到capacity,必须知道如何根据访问频率驱逐对象。
这些注释将保留到我们实现 increment 和 evict 这 2 个函数。
Cache 的第三个函数是 Get – 通过哈希表中的键访问对象并返回它:
func (cache *Cache) Get(key string) interface{} {
if e, ok := cache.bykey[key]; ok {
// Increment acess frequency here
return e.value
}
return nil
}
这里也也没有要说的 – 我们检查哈希表 bykey 是否存在 key,如果存在则返回它。否则,我们返回 nil。这就像在 Set 中一样,我们用注释为频率增加函数占位。
更新访问频率
正如上面看到的,缓存的每个访问操作,都要更新所访问对象的访问频率。让我们看一下 Increment 函数的过程。
首先,对于要更新的对象,我们得先看看它是不是已经在哈希表和频率链表里了。如果是,我们要在在频率链表中找到它的新频率值和下一个频率的位置(节点)。
其次,我们必须弄清楚新频率是不是已经在频率列表中了。如果在,我们要把该对象添加到其 entries 中。如果不在,我们就得在频率链表中创建一个新的频率节点(并设置其所有合理的默认值),然后将该对象添加到其 entries 中。
然后,一旦我们有了新的 FrequencyParent,我们就必须把该对象的父项设置新父项,并将其添加到新父项的 entries 中。
最后,increment 函数要从旧频率节点(frequencyParent)的 entries 中删除该对象。
下面是 Golang 代码:
func (cache *Cache) increment(item *CacheItem) {
currentFrequency := item.frequencyParent
var nextFrequencyAmount int
var nextFrequency *list.Element
if currentFrequency == nil {
nextFrequencyAmount = 1
nextFrequency = cache.freqs.Front()
} else {
nextFrequencyAmount = currentFrequency.Value.(*FrequencyItem).freq + 1
nextFrequency = currentFrequency.Next()
}
if nextFrequency == nil || nextFrequency.Value.(*FrequencyItem).freq != nextFrequencyAmount {
newFrequencyItem := new(FrequencyItem)
newFrequencyItem.freq = nextFrequencyAmount
newFrequencyItem.entries = make(map[*CacheItem]byte)
if currentFrequency == nil {
nextFrequency = cache.freqs.PushFront(newFrequencyItem)
} else {
nextFrequency = cache.freqs.InsertAfter(newFrequencyItem, currentFrequency)
}
}
item.frequencyParent = nextFrequency
nextFrequency.Value.(*FrequencyItem).entries[item] = 1
if currentFrequency != nil {
cache.remove(currentFrequency, item)
}
}
让我们再看看对象 E 原来的频率以及其所在的条目列表:
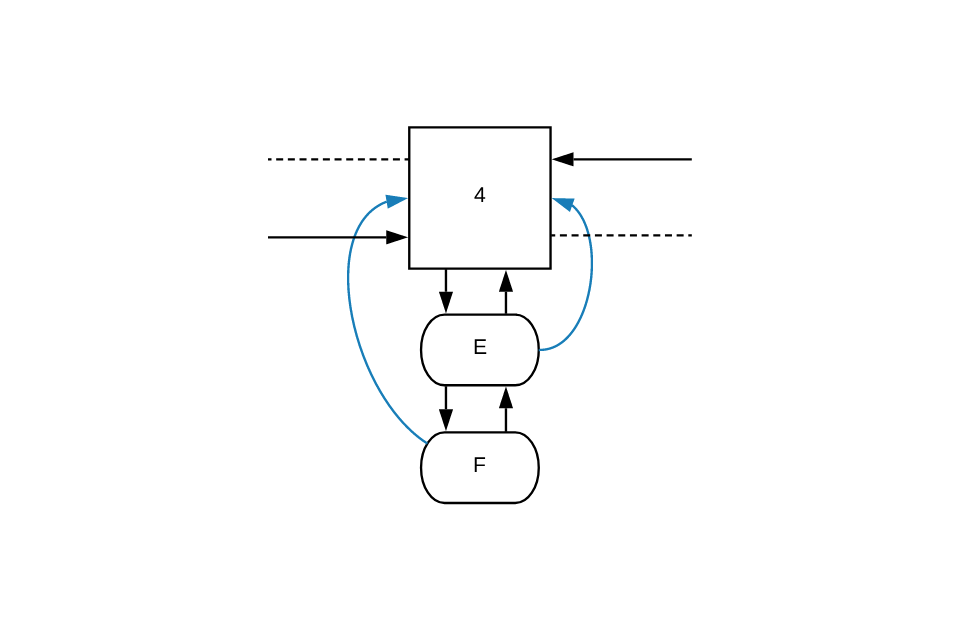
increment 函数第一步是分配一个指向节点 4(frequencyParent)的指针。由于节点 4 存在于列表中,函数会在频率列表中找下一个节点,在我们的例子中找到的是节点 7。
在确定 E 节点的新频率应为 5 而不是 7 之后,它将在节点 4 和 7 之间增加一个新的频率节点:
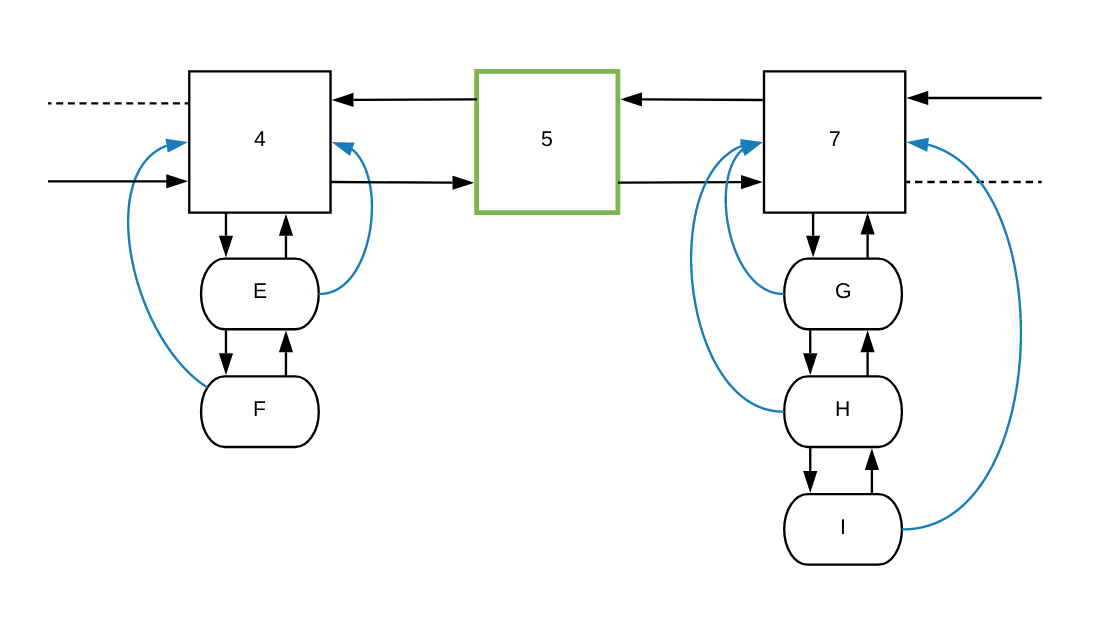
函数会给新节点 5 设置所需的默认值。然后将 E 的指针设置为新的 frequencyParent(节点 5):
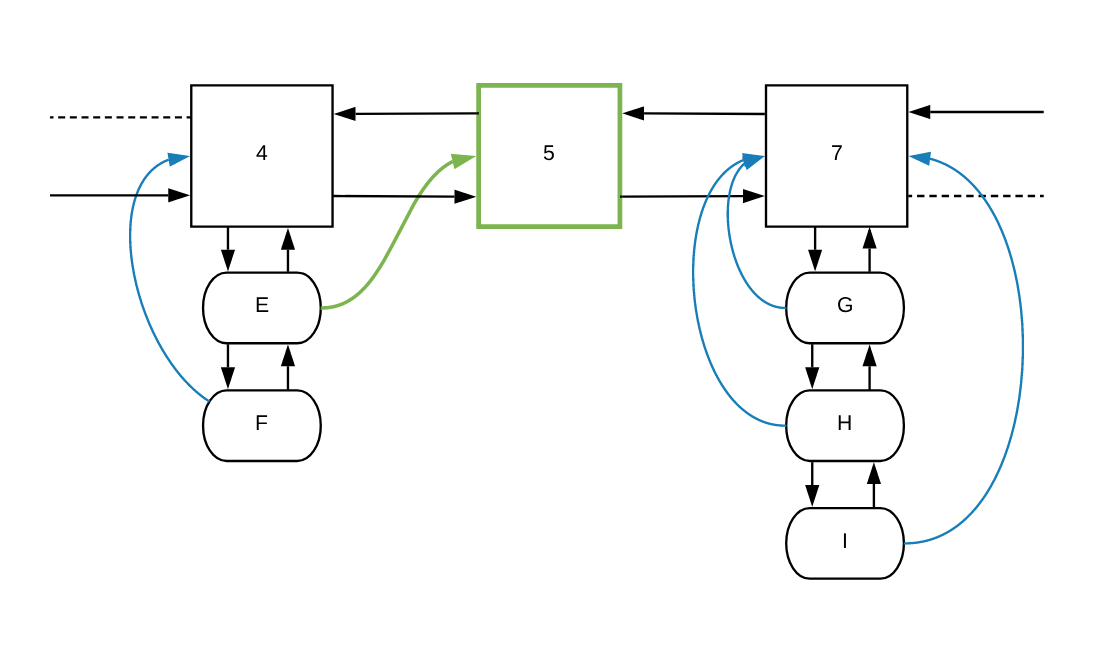
最后一步,它将 *CacheItem 类型的 item 添加到节点 5 的 entries,同时从先前的 frequencyParent 的 entries 中删除它:
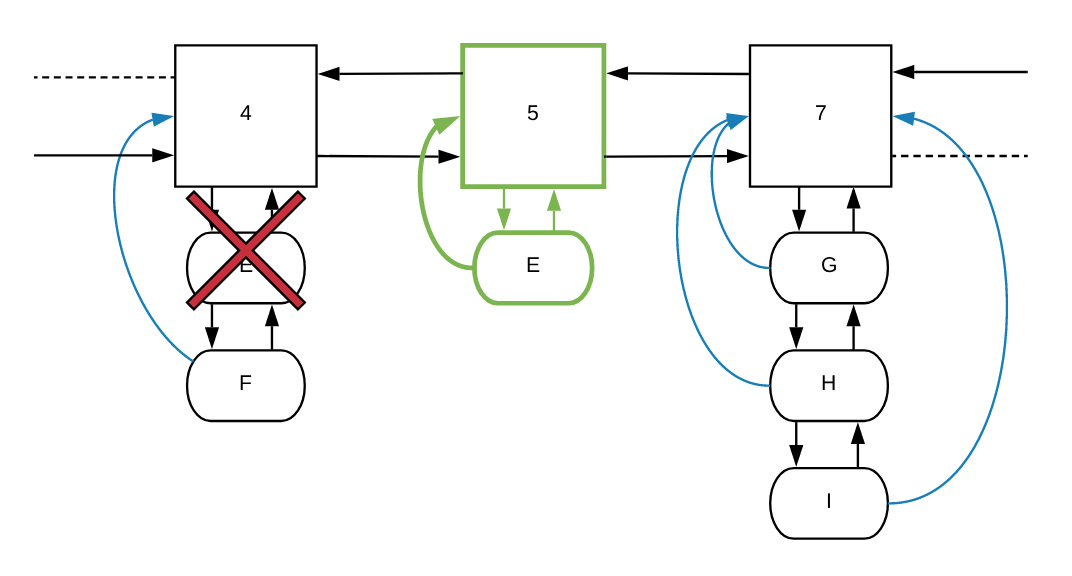
让我们看看怎么从 FrequencyItem 的 entries 列表中删除 CacheItem。
删除 entries
在知道我们想要删除对象指向的频率节点之后,就可以从该节点的 entries 中删除该对象,如果 entries 成空的了,还可以从频率链表中完全删除该 FrequencyItem:
func (cache *Cache) Remove(listItem *list.Element, item *CacheItem) {
frequencyItem := listItem.Value.(*FrequencyItem)
delete(frequencyItem.entries, item)
if len(frequencyItem.entries) == 0 {
cache.freqs.Remove(listItem)
}
}
驱逐
实现的的最后一部分就是驱逐了,或者换句话说,一旦缓存达到其最大容量,就删除最不常用的对象。
我们必须知道我们想要驱逐多少对象。通常,我们的缓存会有下限和上限,因此当达到上限时,我们将删除项目直到下限。在我们的例子中,我们将驱逐任意数量的对象,Evict 函数只有一个参数。
这个函数会“遍历”频率链表。由于频率链表是按升序排列的,因此它将开始从第一个频率节点开始删除 entries,直到它删除的对象数量达到传入的数字。
如果频率节点由于驱逐对象而变成空的,则 Evict 函数也必须从频率链表中移除频率节点,这通过调用 Remove 函数来实现。这样,过程中就不会留下任何垃圾。
这是我们上面描述的代码:
func (cache *Cache) Evict(count int) {
for i := 0; i < count; {
if item := cache.freqs.Front(); item != nil {
for entry, _ := range item.Value.(*FrequencyItem).entries {
if i < count {
delete(cache.bykey, entry.key)
cache.Remove(item, entry)
cache.size--
i++
}
}
}
}
}
回到 Set and Get
在本章开头,我们实现了 Set 和 Get 函数。当时我们没有 Evict 和 increment 这 2 个函数。现在让我们加上它们的调用:
Incrementing access frequency
在 Get 函数中,如果我们在 bykey 哈希表中找到该对象,我们需要在返回 value 之前增加它的访问频率:
func (cache *Cache) Get(key string) interface{} {
if e, ok := cache.bykey[key]; ok {
cache.increment(e)
return e.value
}
return nil
}
改过之后,Cache 将在返回之前增加该对项的频率。但是,我们忘了什么吗?此外,Set 函数在缓存对象时访问缓存的项目。这意味着当一个对象被缓存时,它将立即被添加到频率链表中值为 1 的节点下:
func (cache *Cache) Set(key string, value interface{}) {
if item, ok := cache.bykey[key]; ok {
item.value = value
cache.increment(item)
} else {
item := new(CacheItem)
item.key = key
item.value = value
cache.bykey[key] = item
cache.size++
// Eviction, if needed
cache.increment(item)
}
}
添加对象时驱逐
Set 函数可以让 LFU Cache 的用户缓存许多项目。任何缓存的一个关键组件是,当新对象添加到缓存时,缓存应该知道如何驱逐旧的对象(释放空间)。对于 LFU 缓存,当缓存达到容量时,需要删除最不常用的对象。让我们首先添加一个函数,如果缓存达到其最大容量,它将返回一个 bool:
func (cache *Cache) atCapacity() bool {
return cache.size >= cache.capacity
}
功能很简单:检查 Cache 的当前 size 是大于还是等于 capacity。
现在,把它放到 Set 函数中。一旦我们在缓存中增加了新对象,我们就必须检查缓存是否已达到其最大容量,如果是就从中删除多个旧对象。
简单起见,我们每次达到最大容量时就删除 10 个对象:
func (cache *Cache) Set(key string, value interface{}) {
if item, ok := cache.bykey[key]; ok {
item.value = value
cache.increment(item)
} else {
item := new(CacheItem)
item.key = key
item.value = value
cache.bykey[key] = item
cache.size++
if cache.atCapacity() {
cache.Evict(10)
}
cache.increment(item)
}
}
改过之后,如果在任何时候添加对象时达到缓存的容量,缓存将驱逐最不常用的旧对象。如果你想查看本文的完整代码,可以到这个 gist。
关于扩展能力和时间复杂度的解释
LFU 是一个有趣的驱逐模式,特别是与 LRU 相比,在我看来,它特别自然。虽然其应用有限,但由于该方法的扩展能力,使得论文中解释的算法和背后数据结构非常吸引人。
如果我们重新阅读本文开头提到的论文,我们知道虽然 LFU 不是新闻,但它传统上是使用最小堆实现的,插入,查找和删除的复杂度都是对数时间。有趣的是,在论文作者解释说,他们提出的方法对于每个操作(插入,查找和删除)都是 O(1) 时间复杂度,因为这些操作基于哈希表。此外,链表不会增加时间复杂度,因为我们不会遍历链表 – 我们只是在需要时添加或删除其中的节点(这是一个 O(1) 操作)。
总结
在本文中,我们了解了 LFU 缓存的基础知识。我们确定了最重要的性能指标(命中率,元素测试和驱逐速度)。我们知道虽然它不是最广泛使用的缓存方案,但在某些场景中肯定会非常高效。
然后我们使用了一种在时间复杂度方面可以很好地扩展的方法实现了它。我们量化了驱逐算法和频率增量算法的复杂度。最后,我们进一步探讨了我们用于实现它的方法如何扩展。
如果你想阅读有关该主题的更多信息,请参阅以下几个链接,以丰富你对 LFU 缓存及缓存的了解:
- “An O(1) algorithm for implementing the LFU cache eviction scheme” - Prof. Ketan Shah, Anirban Mitra, Dhruv Matani
- “Caching in theory and practice” - Pavel Panchekha
- “LFU (Least Frequently Used) Cache Implementation” - Geeks for Geeks
本文翻译自 Ilija Eftimov 发表于其博客的文章,原文地址在 When and Why to use a Least Frequently Used (LFU) cache with an implementation in Golang。
