怎么写一个快速的网络服务器?
怎么写一个能处理 10000 个客户端的网络服务器?
有哪些瓶颈?怎么避免它们?
关于我
我做安全顾问为生(我的公司叫 Code Blau)。
我对小型高性能代码十分感兴趣。
除了 web 服务器外,我还写了一个 ftp 服务器、一个快速 LDAP 服务器(目前只能读,我在等着有人赞助我完成它)和一个最小 Unix C 库(我用它编译并运行了这里提到的所有程序)。
我也因在促进 djbdns 支持IPv6、为 mutt 邮件客户端写 FAQ 以及在 Linux 内核邮件列表写有煽动性的 bug 报告这些圈子里为人所知。
为什么需要高性能网络代码
Apache 在很多方面来说够快了。
但是如果你经常访问 Slashdot,你会发现他们链接的站点经常挂掉,因为他们无法处理这些负载。
Slashdot 使用 8 个 P3/600 处理器、1G 内存以及 10k 转 SCSI 硬盘 的服务器。
www.heise.de 使用 4 个 P3/650 处理器 和 1G 内存的服务器。
ftp.fu-berlin.de 用的是 2 个 R10k/225 处理器、1G 内存和 10k 转 SCSI 硬盘的SGI Origin 200 服务器。
显然可以通过购买更多的硬件扩展性能,但是我们怎么能保证软件不是瓶颈呢?
为什么处理许多连接这么重要
一个互联网玩具商店给我打了一次电话。那是 12 月的一个雨天。
这是他们圣诞季节最赚钱的时候。
打电话原因是他们的 web 服务器正遭受攻击。这些分布式攻击在他们的服务器上开了 100000 个 HTTP 连接。
这让他们每一个负载均衡的 Solaris 后端都产生了 20000个 Apache 进程。这些机器在绝望地内存置换。
在他们的网站买东西是不可能了。
我觉得他们实际是怕破产。
首先我们写一个 web 客户端
char buf[4096];
int len;
int fd=socket(PF_INET,SOCK_STREAM,IPPROTO_TCP);
struct sockaddr_in si;
si.sin_family=PF_INET;
inet_aton("127.0.0.1",&si.sin_addr);
si.sin_port=htons(80);
connect(fd,(struct sockaddr*)si,sizeof si);
write(fd,"GET / HTTP/1.0\r\n\r\n");
len=read(fd,buf,sizeof buf);
close(fd);
这是什么?
好吧
-
我没有包含任何头文件
-
没有错误处理
-
这个客户端只能获取 4K 的数据(包括 HTTP 头)
-
你不能指定 URL
但除了这些:是的,这相当多了
好了,让我们写一个 web 服务器
int cfd,fd=socket(PF_INET,SOCK_STREAM,IPPROTO_TCP);
struct sockaddr_in si;
si.sin_family=PF_INET;
inet_aton("127.0.0.1",&si.sin_addr);
si.sin_port=htons(80);
bind(fd,(struct sockaddr*)si,sizeof si);
listen(fd);
while ((cfd=accept(fd,(struct sockaddr*)si,sizeof si)) != -1) {
read_request(cfd); /* read(cfd,...) until "\r\n\r\n" */
write(cfd,"200 OK HTTP/1.0\r\n\r\n"
"That’s it. You’re welcome.",19+27);
close(cfd);
}
这个服务器烂透了
这个服务器(并且没有声明协议)一次只能处理一个客户端。这样会更好:
while ((cfd=accept(fd,(struct sockaddr*)si,sizeof si)) != -1) {
if (fork()>0) continue; /* handle connection in a child process */
read_request(cfd); /* read(cfd,...) until "\r\n\r\n" */
write(cfd,"200 OK HTTP/1.0\r\n\r\n"
"That’s it. You’re welcome.",19+27);
close(cfd);
exit(0);
}
每个连接一个进程 – 这样好么?
那是守旧的学术派方式。自从 70 年代就一直这样做。
CERN 的第一个服务器就是用的这种方法。

每个连接都创建一个进程确实有扩展性问题。这样很难正确实现 fork() 函数。下面是基准测试程序:
pipe(pfd);
for (i=0; i<4000; ++i) {
gettimeofday(&a,0);
if (fork()>0) {
write(pfd[1],"+",1); block(); exit(0);
}
read(pfd[0],buf,1);
gettimeofday(&b,0);
printf("%llu\n",difference(&a,&b));
}
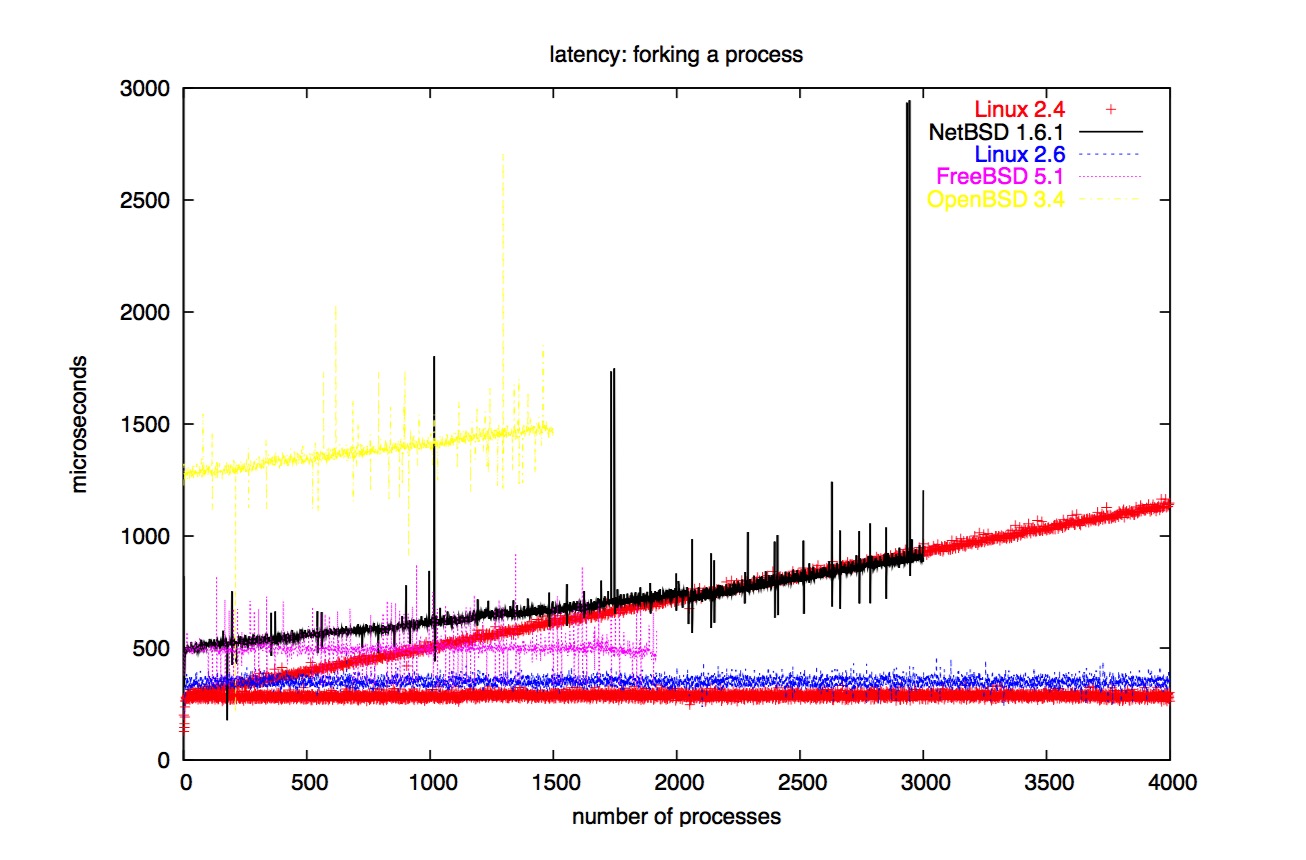
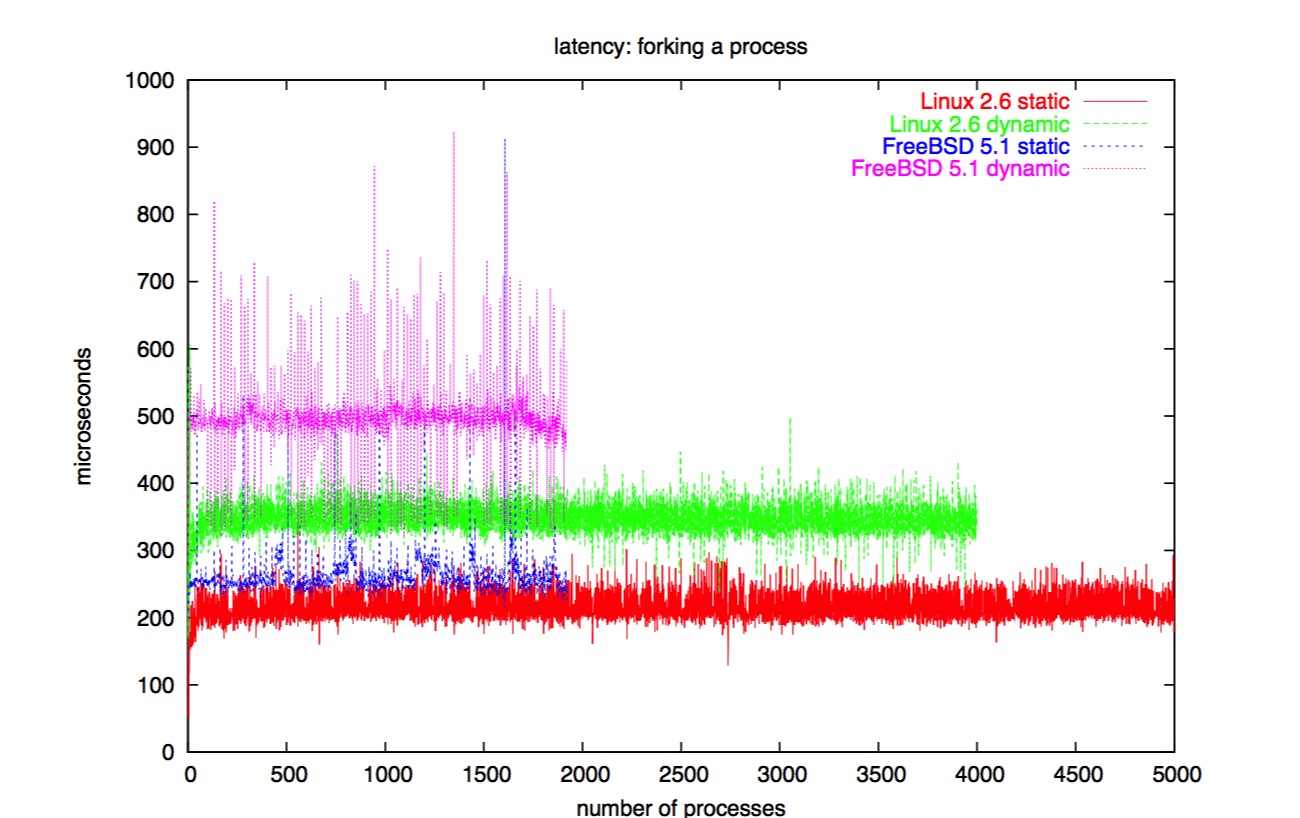
fork: 动态连接 vs 静态连接
另外一个影响 fork 性能的重要因素是 fork 干了多少工作。
在带有内存管理单元的现代平台上,fork 仅仅拷贝页映射。
动态连接会为共享库中的 ELF 段、全局偏移表等创建许多页映射。
因此,静态连接 fork 基准测试程序会明显地提高性能。
确保你理解了这些数字
在我 Linux 2.6 的笔记本上,fork-and-do-something 模式的开销为 200 微秒。
这意味着我的笔记本每秒能创建 5000 个进程。
因此我的笔记本每月能处理 130 亿请求。
而我的 Athlon XP 2000+ 每秒能创建 10000 个进程,每月就是 260 亿。
Heise Online,最大的德国网站,在九月份有高达 1180 亿次页面访问。
调度
为什么 fork 的基准测试程序包括向管道写数据?
因为拥有很多进程不仅会使创建更多进程变得更困难,也会使选择哪个进程去执行变得更难。
操作系统里选择下一次哪个进程执行的部分叫做调度器。
一种典型的工作负载是有 2 打进程,而只有其中的 1 个或 2 个在实际做事情(他们是可运行的)
Linux 每 1/100 秒就会中断一次正在运行的进程(在 Alpha 上是 1/1000;该值在 Unix 和 Linux 上一般叫做 HZ,是一个编译时常量)来给其他进程运行的机会。
调度器在一个进程阻塞时(例如等待输入)也会激活。
调度器的工作是选择下一个该运行的进程。难点在于公平原则:所有的进程应该得到相同的 CPU 时间。通常,进程不应该饿死。
使用 2 个列表明显很有意义:一个放可运行的进程,另一个放阻塞的进程。
Unix 有偏爱交互式进程而不是批处理任务的机制。为了实现这个,内核为一个进程每秒都要计算一个 nice 值。
当有 10000 个进程时,这就和二级缓存相悖。
尤其是对于 SMP 处理器更糟糕,因为进程表一定被一个自旋锁保护,例如,在第一个 CPU 计算 nice 值的时候,其他 CPU 无法切换进程。
商业 Unix 通常的解决方案是每个 CPU 一个运行队列。更进一步的优化包括保持运行队列有序,比如使用堆;或者每个优先级一个运行队列。
Linux 2.4 的调度器
Linux 的调度器将所有的可运行进程放在一个无序的运行队列中;将所有的睡眠进程和僵尸进程放在一个任务列表中。
运行队列上的所有操作都被一个自旋锁保护。
Linux 2.4 也有几个实验性的调度器,如基于堆的优先级队列 和 多运行队列,但是最令人惊叹的是 Ingo Molnar 的 O(1) 的调度器。
O(1) 调度器在 Linux 2.6 是默认的调度器。
Linux 2.6 的调度器
O(1) 调度器有 2 个指针数组,指针指向每个 CPU 都有一个链表。对于每一个可能的优先级,数组都有一个入口。
链表包含该优先级的所有任务。既然在每个链表上的任务拥有相同的优先级,将给定优先级的进程放进该数据结构只花费常数时间。
其中一个数组是当前的运行队列;里面的所有进程被轮流执行,而当他们用光自己的时间片就会被移到另外一个数据。当运行队列为空是,2 个数组被交换一下。
调度器中断的进程被认为是批处理进程并会被惩罚。这比偏爱交互式进程的代价小多了。
调度器的性能有多重要
调度器每秒运行 100 次(实际上是 HZ),加上每次进程阻塞。
每次调度器休眠一个进程切换到另外一个进程时,操作系统的一个计数器会加 1。
这个 “上下文切换” 计数器可以使用 vmstat 看到。
上下文切换的代价跟架构有关。一般来说,寄存器越多上下文切换越昂贵。因此 X86 相比 RISC 有不公平的优势,相比 SPARC 和 IA64 更是如此。
下面是运行一个 MP3 播放器时 vmstat 的输出:

下面是在 lo 和 eth0 上运行一个 httpbench 的输出:

运行过多进程的其它问题
最大的问题就是内存消耗。
每个进程都占用内存。当一个进程 fork 子进程的时候,它的内存页被设置成写时拷贝(copy-on-write)。只要有一个进程修改了内存页,就会拷贝一份。
这看起来很好,但很多人没意识到他们的程序要修改多少内存。
例如,在调用 malloc 或者 free 时,可能会造成合并数据结构或者平衡 free 列表里的一些树。
另一个例子是动态链接器,它维护一个全局偏移量表,但默认情况下它非常懒,只有在函数第一次调用的时候才去更新。
因此如果你在 fork 之后第一次调用一个函数,且 fork 了 1000 个子进程,你就会浪费 1000 个 4K 页。
你可以通过设置环境变量 $LD_BIND_NOW 来告诉动态加载器在程序一开始就更新所有的偏移量。
要记住清理 1000 个进程比 fork 1000 个进程还要慢,并且所有的测试系统在这段时间内都不相应。
内存消耗
在 Unix 测量你自己的内存消耗并不简单。
系统调用 getrusage 可以干这个事情,但在 Linux 上总是返回 0,在 FreeBSD 上只返回动态链接的程序的数据。
在 Linux 中,/proc/self/statm 包含的数据:

一个连接一个进程模型
这个模型工作挺好,也有标准工具。
Unix 的 inetd 服务器不仅为每一个连接都 fork 一个子进程,而且为每一个连接执行一个外部程序。
不幸的是,inetd 给它自己(和整个网络编程模型)起了个坏名字,因此人们实现了自己服务器,像 tcpserver、xinetd 和 ipsvd。
这比简单 fork 稍微低效,但优点是标准化了 IP 访问控制机制。
我也用这个模型写了自己的 web 服务器 fnord。现在它还跑着 www.fefe.de。
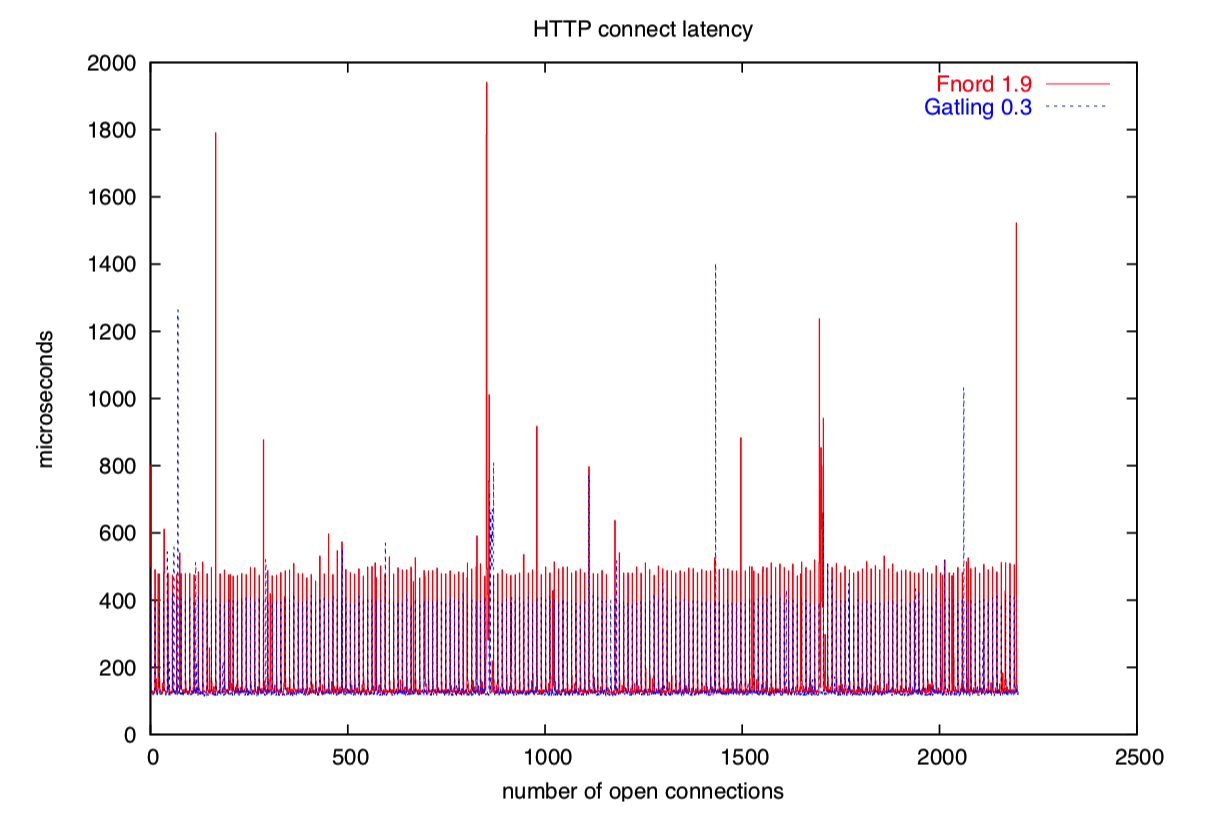
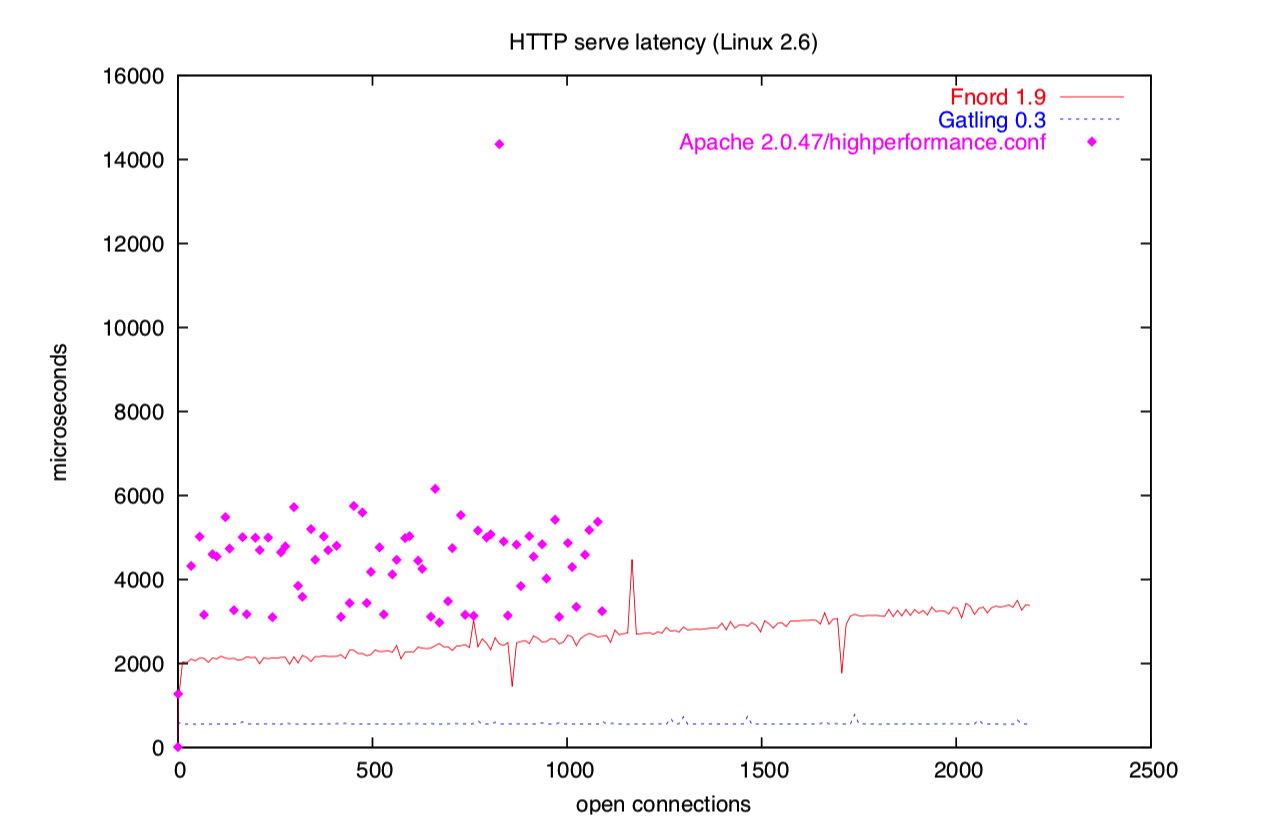
Apache 也使用一个连接一个进程的模型。
然而,为了减少 fork 的开销,Apache 采用预 fork,也就是它先 fork 进程,然后接收 HTTP 连接并指派给子进程处理。
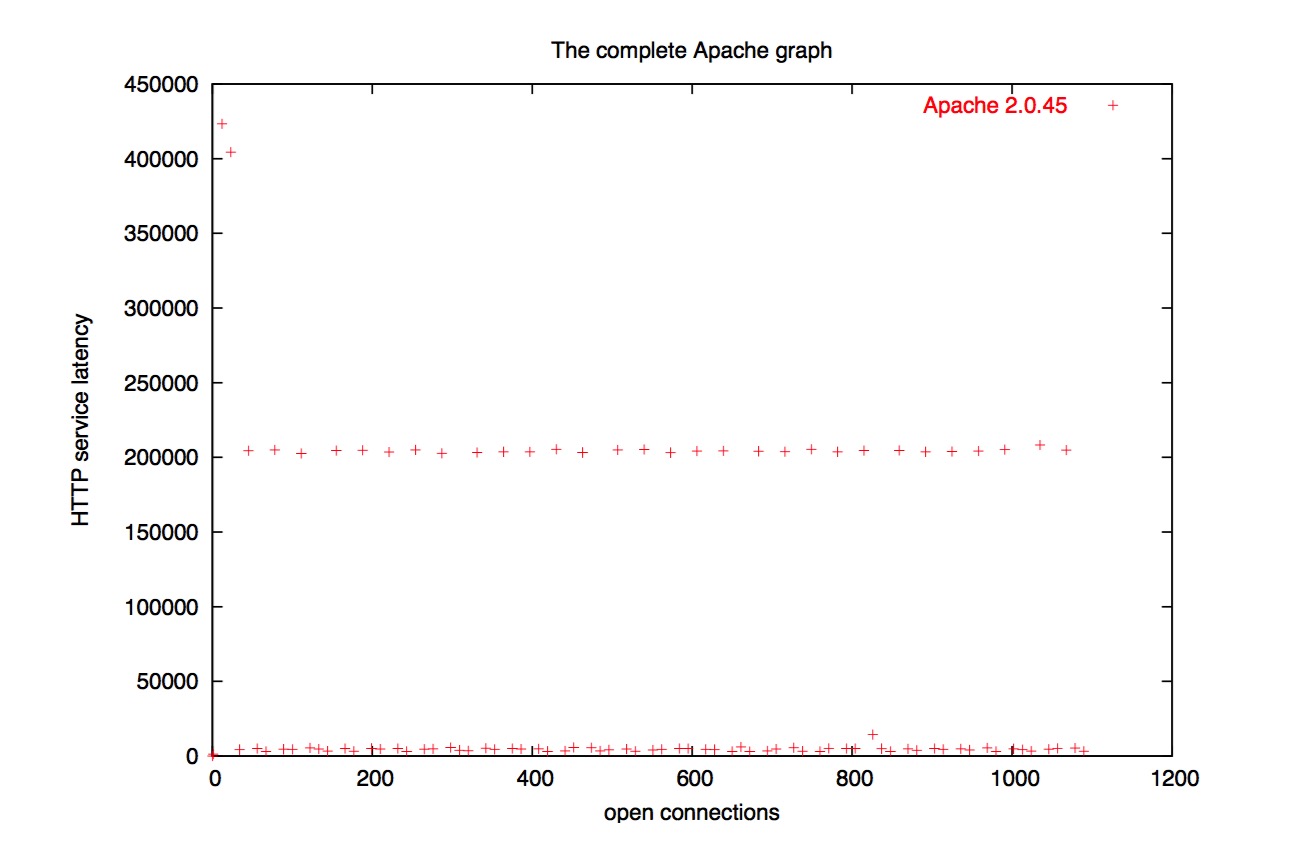
但是等一下!你们现在还没有见过完整的 Apache 图示!
我删掉了很大一部分,因为在组合图示中,你会看不到 gatling 和 fnord 的测试结果。
总之,Apache 的性能烂透了。
既然进程这么慢,为什么不使用线程
总所周知 fork 很慢,那我们为啥不用线程呢?
真相很复杂。
如你所见,fork 也不总是那么慢。但在某些系统上,fork 是相当慢,其中之一就是 Solaris。
很明显很难去修复 fork(或许所有的工程师忙于发明 Java),因此出现了线程。
两年前,我测试在相同的硬件上 Solaris 的 pthread_create 比 Linux 上面的 fork 还要慢。然而,我现在没有权限使用那个硬件,因此没有那个图了。但我有这个:
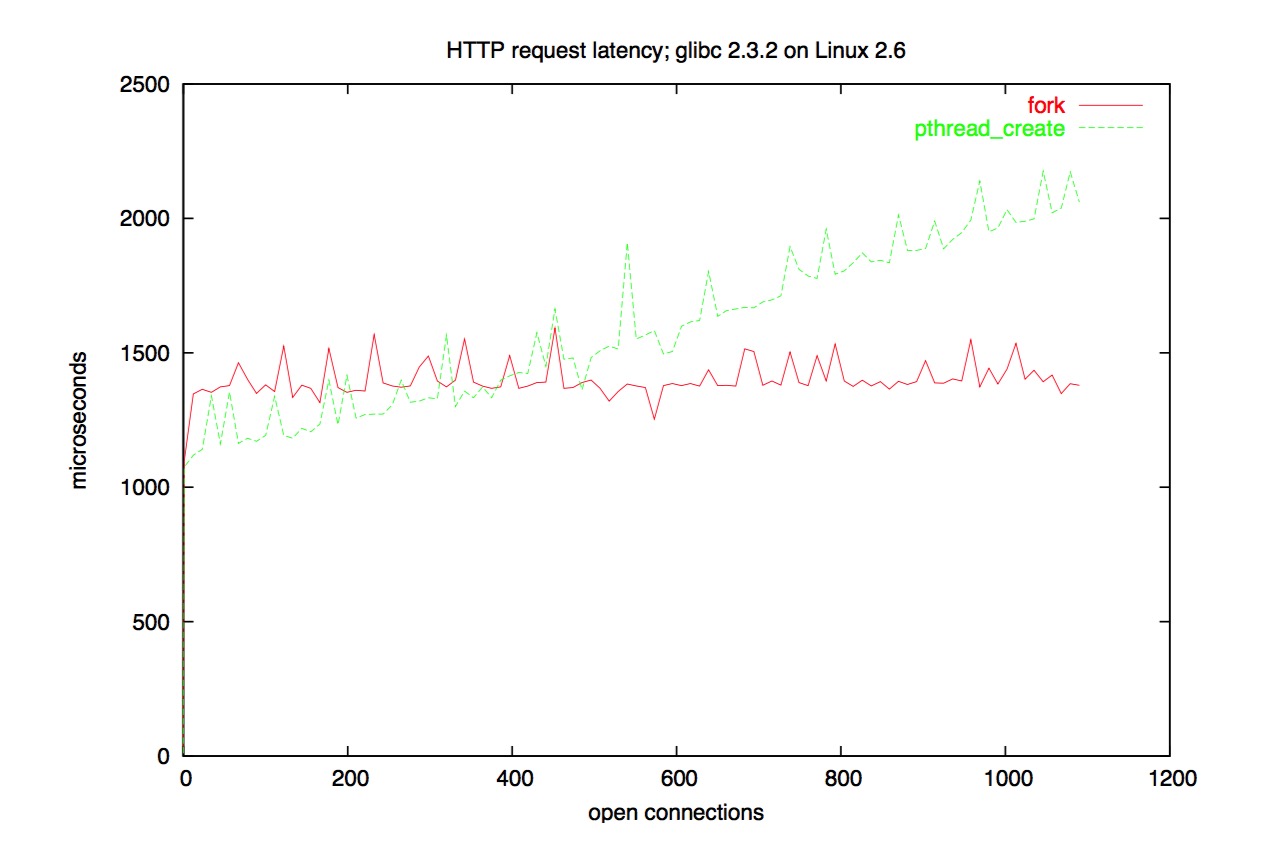
多线程的性能
线程的一个问题是在糟糕的操作系统上,创建线程依然很慢。Solaris 和 Windows 创建线程可能比创建进程快一点,但依旧很慢。
那他们该怎么办呢?他们发明了线程池。
线程池就像 Apache 的 pre-fork。一些线程在程序开始的时候被创建,然后在那里阻塞,任务会均匀分配给线程。
当连接数超过线程数时,新的连接就必须等待。但另一方面,你节省了线程创建的代价。
我不知道你怎么看,反正我不会称它是可扩展的。
线程好的一面
对于 Java 和线程来说也有好的一面,那就是我们现在有更新的、更快的硬件了,并且 RAM 的价格也越来越低。
对于软件也是一样:应用程序的白痴迫使操作系统进行伟大的创新。由于 Lotus Notes 为每一个打开的客户端都保持一个 TCP 连接,因此 IBM 致力于优化在 Linux 一个进程能 hold 住 100000 连接。
O(1) 的调度器在不相干的 Java 基准测试也跑得很好。
底线是对大家都有好处。我们只需要确保对于所有垃圾软件都有小而有效的替代。
处理完成后的超时怎么处理
对于网络服务器来说,一个重要的问题是:如何检测超时。
网络服务器需要检测客户端什么时候占着连接啥事不干。
无论网络服务器如何优化,你(和操作系统)总是要保持已建立的连接状态,它们花费的系统资源要比处理活跃连接少一些。
Unix 有一个标准函数 alarm 适合做这事:
` alarm(23); /* deliver SIGALRM in 23 seconds */ `
收到一个未处理的信号会终止该程序。
因此,23 秒后系统会终止 web 服务器。
后调用的 alarm 会覆盖之前的调用。
你就可以简单地每次在套接字活跃的时候调用 alarm。
使用 select 处理超时
select 等待一个或多个文件描述符的事件(select 1983 年出现在 BSD 4.2 上)。
fd_set rfd;
struct timeval tv;
FD_ZERO(&rfd); FD_SET(0,&rfd); /* fd 0 */
tv.tv_sec=5; tv.tv_usec=0; /* 5 seconds */
if (select(1,&rfd,0,0,&tv)==0) /* read, write, error, timeout */
handle_timeout();
if (FD_ISSET(0, &rfd))
can_read_on_fd_0();
超时时间值以微秒给出,但没有 Unix 系统能精确到微秒,第一个参数是最大的文件描述符加 1。/呕吐
select 的缺点
select 并不告诉你它等待事件等了多久,因此你仍需要手动调用 gettimeofday()。实际上,在 Linux 上 select 会告诉你,但这是不可移植的。
select 使用位向量工作。向量的大小取决于操作系统。如果你足够幸运,你可以有 1024 个(如在 Linux 上)。其他类 Unix 系统会更少。
这比看起来还要糟糕。一些糟糕的 DNS 库使用 select 来处理超时。如果你打开了 1024 个文件,DNS 会突然停止工作,因为 DNS 的套接字数量超过了 1024!Apache 通过手动保持文件描述符不少于 15 个空闲来解决这个问题。(使用 dup2)。
使用 poll 处理超时
poll 相当于 select 的一个变体(poll 在 1986 年出现在 System V R3 上)。
struct pollfd pfd[2];
pfd[0].fd=0; pfd[0].events=POLLIN;
pfd[1].fd=1; pfd[1].events=POLLOUT|POLLERR;
if (poll(pfd,2,1000)==0) /* 2 records, 1000 milliseconds timeout */
handle_timeout();
if (pfd[0].revents&POLLIN) can_read_on_fd_0();
if (pfd[1].revents&POLLOUT) can_write_on_fd_1();
优点:没有了记录数和文件描述符数的限制
缺点:poll 在一些“博物馆展览”上不可用。当前只有一个“Unix”操作系统通过不提供 poll 来取消它自己网络操作系统的资格:MacOS X。
poll 的缺点
整个数组是没有必要在用户空间和内核空间拷来拷去。仅为了内核找到事件并设置对应的 revents。
当前的 CPU 花费了大量的时间来等待内存。poll 让其变得更糟糕。并且浪费会随着描述符的增多而线性增长。
这其实也不像看起来那么坏。如果 poll 花费时间较长,事件并不会丢失。内核会将这些时间入队,在下一次 poll 的时候通知它们。
另一方面,在 Linux 和 FreeBSD 上,使用 fork 的 web 服务器比使用 poll 的扩展性更好。
Linux 2.4:SIGIO
Linux 2.4 可以通过信号来告诉你 poll 的事件。
int sigio_add_fd(int fd) {
static const int signum=SIGRTMIN+1;
static pid_t mypid=0;
if (!mypid) mypid=getpid();
fcntl(fd,F_SETOWN,mypid);
fcntl(fd,F_SETSIG,signum);
fcntl(fd,F_SETFL,fcntl(fd,F_GETFL)|O_NONBLOCK|O_ASYNC);
}
int sigio_rm_fd(struct sigio* s,int fd) {
fcntl(fd,F_SETFL,fcntl(fd,F_GETFL)&(~O_ASYNC));
}
SIGIO 并不是 poll 的替代品。poll 告诉你什么时候描述符可读了,而 SIGIO 告诉你它是什么时候变得可读的。
如果 poll 通知你可以读描述符 3 了,而你并没有读,那下一次 poll 还会通知你。而 SIGIO 不会。poll 行为被称为水平触发,而 SIGIO 称为边缘触发。
最好的获取事件的方式是 sigtimedwait,在你阻塞 SIGIO (信号)和 signum 之后。它会同步恢复并避免需要锁和可重入函数。
for (;;) {
timeout.tv_sec=0;
timeout.tv_nsec=10000;
switch (r=sigtimedwait(&s.ss,&info,&timeout)) {
case -1: if (errno!=EAGAIN) error("sigtimedwait");
case SIGIO: puts("SIGIO queue overflow!"); return 1;
}
if (r==signum) handle_io(info.si_fd,info.si_band);
}
info.si_band 和 pollfd.revents 是完全相同的。
SIGIO 的缺点
SIGIO 也有缺点。内核有一个事件队列,并且事件按顺序传递。内核可能在一个你已经关闭的描述符上通知事件。
事件队列长度固定,你不能说你想要多大。如果队列满了,你会得到一个 SIGIO 信号,但不是事件通知。
然后你会想要清洗队列(通过设置 signum 的处理函数为 SIG_DFL),并使用 poll 获取事件。
这个 API 减少了内存传输,但每个事件都要使用一个系统调用。虽然在 Linux 上系统调用时廉价的,但并不是免费的。
处理队列溢出是很恼人的。poll 也有同样的问题:你不会想维护 pollfd 数组。
pollfd 数组怎么了?
我们写了一个 web 服务器。poll 告诉我们可以读描述符 5 了。而 read 告诉我们这个连接已经关掉了。我们现在要关闭这个描述符并将记录从数组中移除。
我们该怎么做?我们不能仅仅将数组中的事件置 0。因为 poll 会以 EBADF 终止并将 revents 设置为 POLLNVAL。因此我们要将数组最后的描述符拷贝到这个位置从而减少数组长度。
现在数组位置 5 不再存放描述符 5 了。因此我们需要一个额外的索引数组来找到该描述符的pollfd。该索引数组需要能伸能索能维护。这很丑陋,也很容易犯错。
并且是相当多余的。
/dev/poll
几年前,Sun 给 Solaris 增加了一个新的 poll 风格 API。你打开 /dev/poll 设备,并将 pollfd 写进该设备。然后就可以使用 ioctl 来等待事件了。ioctl 会返回这里有多少事件,以及接下来有多少 pollfd 可以从该设备读了。这个设备只会告诉你实际活跃的 pollfd。
这意味着你不用为了某个事件儿扫描整个数组了。
在 Linux 上有几种方法来创建这样的设备,但没有一种完全纳进了内核。
噢,还要说的是这些补丁在高负载情况下不稳定。
/dev/epoll
Linux 在 2.4 版本增加了 /dev/epoll 设备。
int epollfd=open("/dev/misc/eventpoll",O_RDWR);
char* map;
ioctl(epollfd,EP_ALLOC,maxfds); /* hint: number of descriptors */
map=mmap(0, EP_MAP_SIZE(maxfds), PROT_READ, MAP_PRIVATE, epollfd, 0);
你可以通过向设备写入 pollfd 来告知你感兴趣的事件;通过向设备写入一个 event = 0 的pollfd 来告知不再对某个事件感兴趣。
这些事件可以通过 ioctl 来获取。
struct evpoll evp;
for (;;) {
int n;
evp.ep_timeout=1000;
evp.ep_resoff=0;
n=ioctl(e.fd,EP_POLL,&evp);
pfds=(struct pollfd*)(e.map+evp.ep_resoff);
/* now you have n pollfds with events in pfds */
}
由于使用 mmap,实际上并没有在内核和用户空间之间拷贝数据。
/dev/epoll 的缺点就是它只是一个补丁。Linus 不喜欢在内核中加入新的伪设备。
他说我们已经在内核中为 syscall 开发了一个调度器,因此我们不想再加其他东西了,我们可以加一个 syscall 而不是一个设备或者 ioctl。
因此,/dev/epoll 的作者使用 syscall 重做了该 API。这个 API 在 Linux 2.5 合入了内核(甚至在 2.5.21 加入了文档)。
在 Linux 2.6 中成为了推荐的事件通知 API。
epoll
int epollfd=epoll_create(maxfds);
struct epoll_event x;
x.events=EPOLLIN|EPOLLERR;
x.data.ptr=whatever; /* you can put some cookie here */
epoll_ctl(epollfd,EPOLL_CTL_ADD,fd,&x);
/* changing is analogous: */
epoll_ctl(epollfd,EPOLL_CTL_MOD,fd,&x);
/* deleting -- only x.fd has to be set */
epoll_ctl(epollfd,EPOLL_CTL_DEL,fd,&x);
EPOLLIN 等常量和 POLLIN 值是相同的,但作者想要把所有的选项都打开。epoll 开始使用了边缘触发,但默认是水平触发。使用 |EPOLLET 可以切换到边缘触发。
下面示例是如何获取事件:
for (;;) {
struct epoll_event x[100];
int n=epoll_wait(epollfd,x,100,1000); /* 1000 milliseconds */
/* x[0] .. x[n-1] are the events */
}
注意 epoll_event 并不包含实际的描述符。
这就是为什么这个 API 是一个小甜点了。你可以把文件描述符放在那里,也可以放一个指向该连接的一些上下文数据结构的指针。
FreeBSD:kqueue
kqueue 介于 epoll 和 SIGIO 之间。既可以像 epoll 一样使用水平触发和边缘触发,也可以做文件和文件夹的状态通知。问题是:这个 API 并没有广泛使用,也没有很好的文档。
kqueue 比 epoll 要早。我认为 Linux 应该简单地实现 kqueue 而不是重新发明 epoll,但 Linux 人坚持要犯一下其他人犯过的所有错误。例如,epoll 作者最开始认为他可以摆脱水平触发。
epoll 和 kqueue 的性能是接近的。
kqueue 也在 OpenBSD 上实现了,但没有在 NetBSD。
下面是你如何告知是否对一个事件感兴趣的示例:
#include <sys/types.h>
#include <sys/event.h>
#include <sys/time.h>
int kq=kqueue();
struct timespec ts;
EV_SET(&kev, fd, EVFILT_READ, EV_ADD|EV_ENABLE, 0, 0, 0);
ts.tv_sec=0; ts.tv_nsec=0;
kevent(kq, &kev, 1, 0, 0, &ts); /* I want to read */
EV_SET(&kev, fd, EVFILT_READ, EV_DELETE, 0, 0, 0);
ts.tv_sec=0; ts.tv_nsec=0;
kevent(kq, &kev, 1, 0, 0, &ts); /* I’m done reading */
下面是你如何获取事件的示例:
struct kevent ev[100];
struct timespec ts;
ts.tv_sec=milliseconds/1000;
ts.tv_nsec=(milliseconds%1000)*1000000;
if ((n=kevent(io_master,0,0,y,100,milliseconds!=-1?&ts:0))==-1)
return -1;
for (i=0; i<n; ++i) {
if (ev[i].filter==EVFILT_READ) can_read(ev[i].ident);
if (ev[i].filter==EVFILT_WRITE) can_write(ev[i].ident);
}
Windoze:完整的接口
甚至微软也要提供一个这样的功能。
微软的做法是使用一个线程池,每个线程池都运行类似 SIGIO 机制的东西。
这完美结合了线程池和 SIGIO 的缺点。
很惊叹微软的市场部是怎么把这玩意儿吹嘘成史诗般的创新的!
我在文档里发现了这句话:毕竟线程这些系统资源既不是无限的也不廉价。
哈?不廉价?我猜这才是这玩意儿存在的原因。
高开销的其他原因
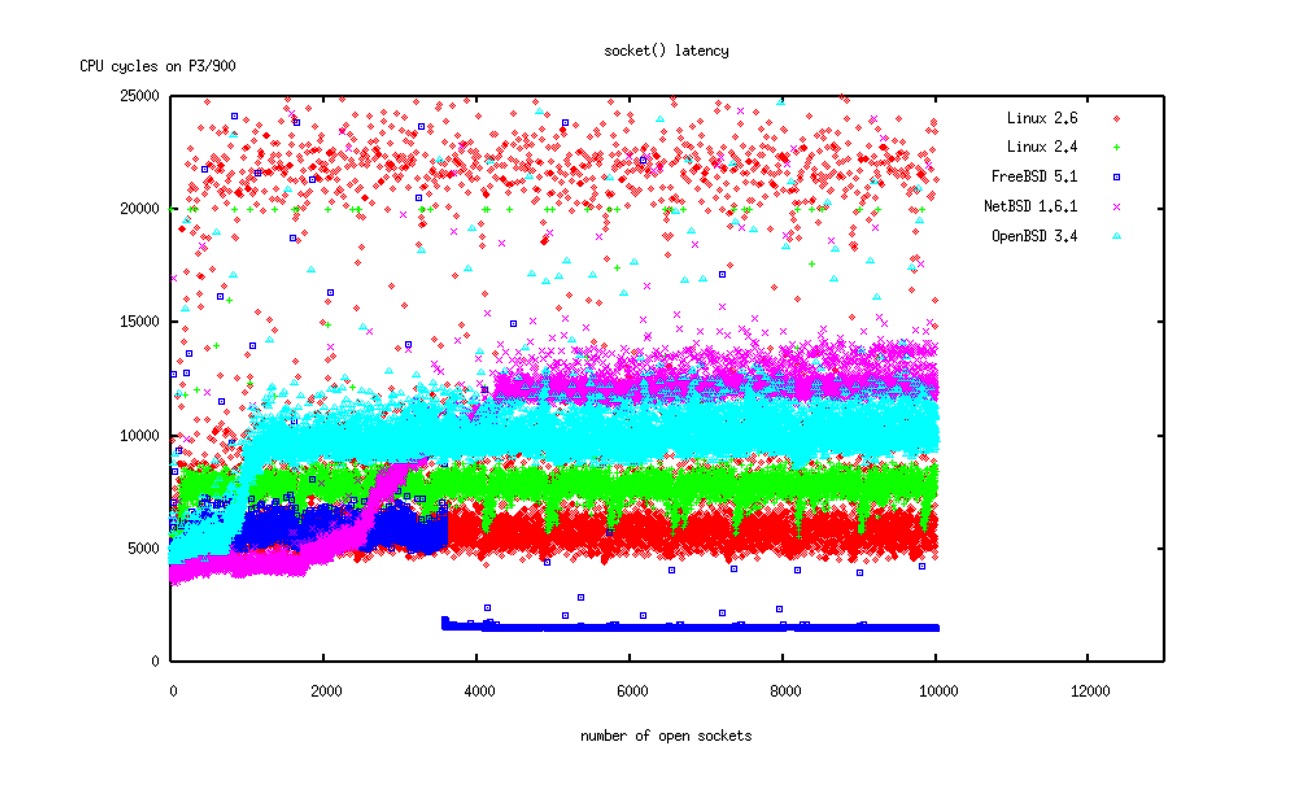
POSIX API 规定内核必须在打开文件时使用最低未使用的文件描述符(比如再接受一个连接时打开一个文件来创建套接字)。
没有方法能做到 O(1)。Linux 使用了位向量。
Linux 内核邮件列表有过很多次讨论增加一个标志来允许返回一个更高的文件描述符,但至今都没有实现。并且这对于套接字也没啥用。
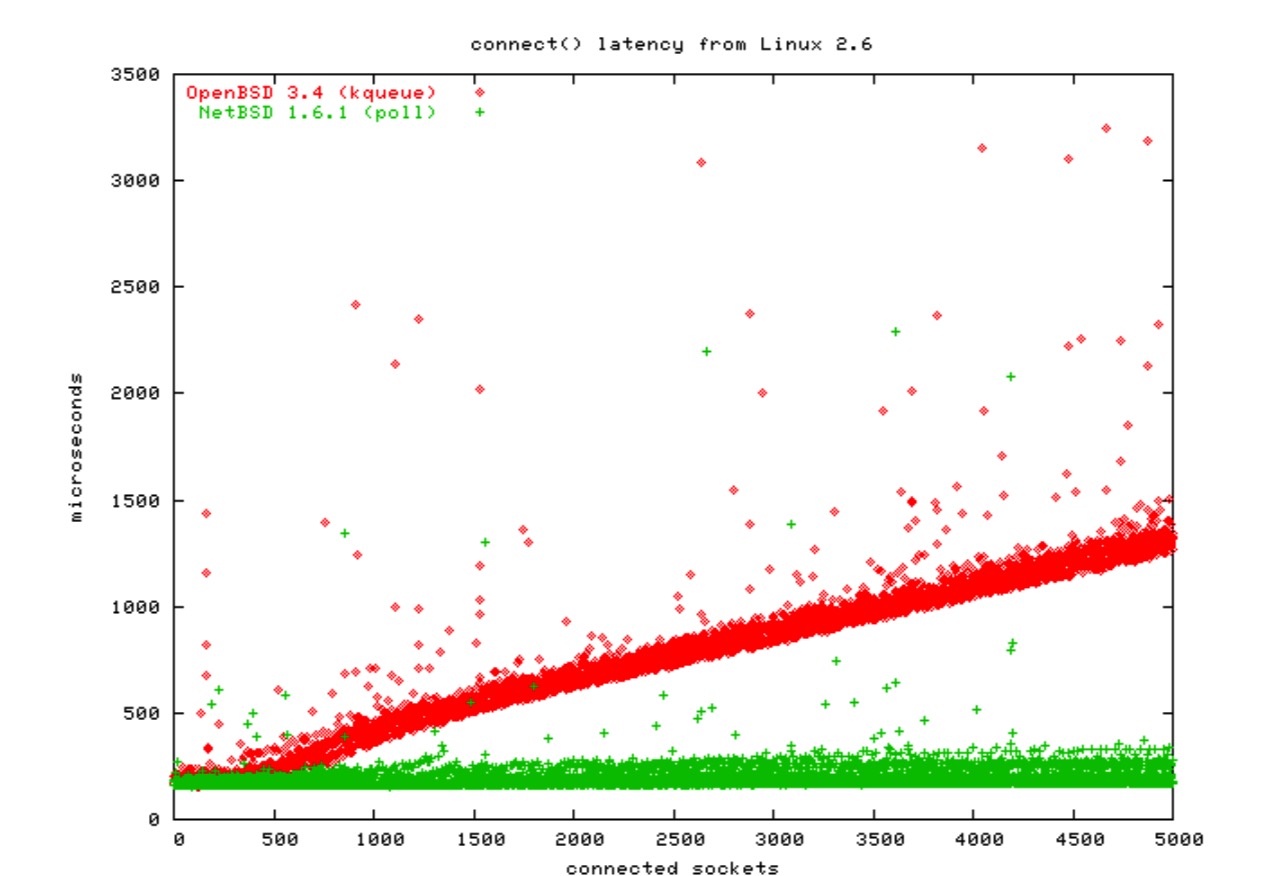
对于 Linux 和所有的 BSD 来说,这一点平衡的很好。如图:
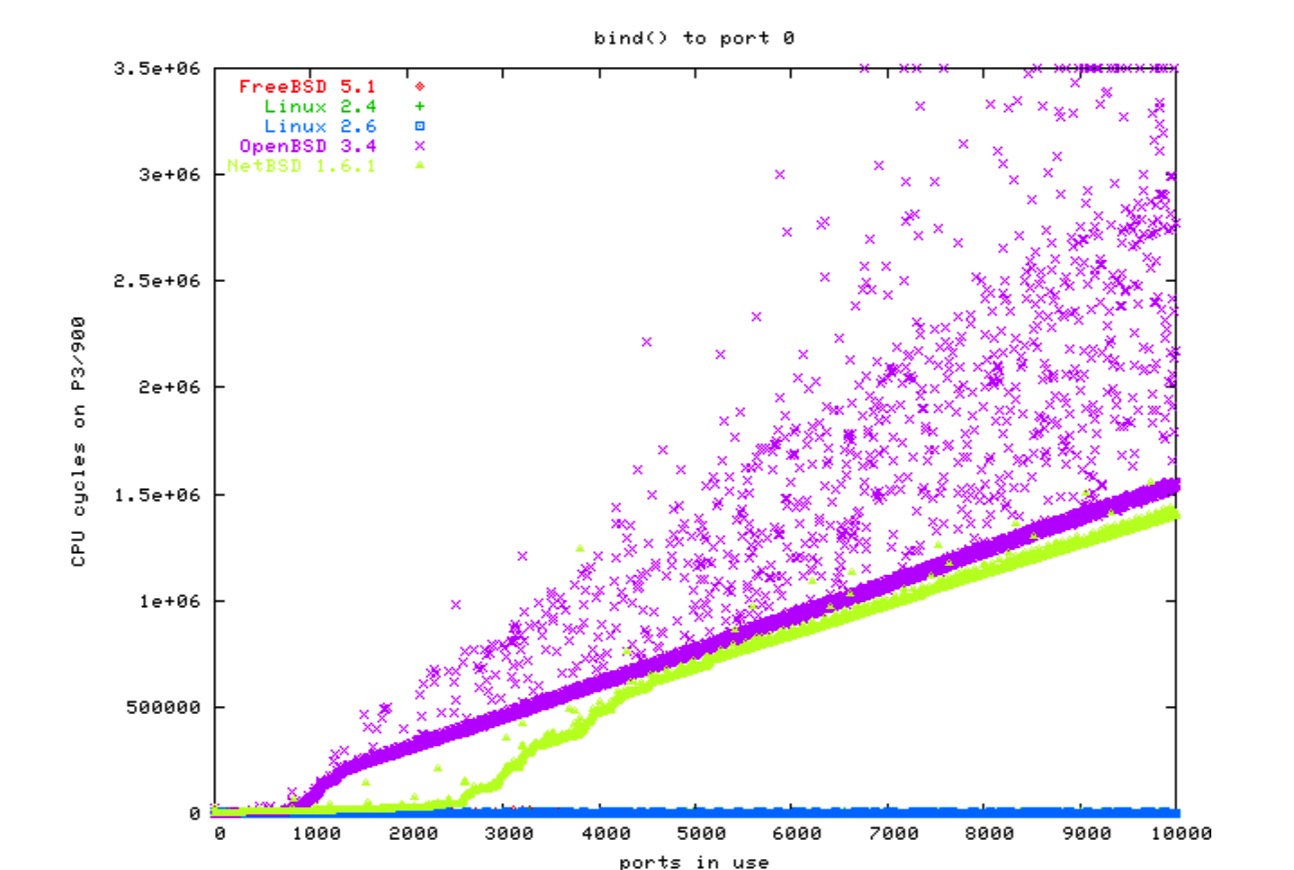
客户端和代理有类似的问题。
当客户端打开一个套接字连接服务器时,如果没有指明端口(译注:本地端口)内核就会为你选择一个空闲的。
虽然没有标准说必须要使用最低的端口,但通常被由于问题而被忽视。
我的测试表明 IPv4 和 IPv6 在任何系统上都没有明显的差异,因此这里只有 IPv4 的图:
碎片和寻道
硬盘在循序读取的时候很快,但在必须移动磁头的时候很慢(如寻道)。
这就是为什么很多大服务器使用 10k 甚至 15k rps 的磁盘。
磁盘的生产力在不久之前就不再是主要关心的问题。
这里有一个图。硬盘每秒能处理 25MB 的数据,是最快的网卡的两倍多。我在 lo 网卡上开启了一个和其他文件竞争的下载,限速到了 5MB/s。这个网卡的下载力低了一半。
下图展示了文件碎片如何降低读取速度的:
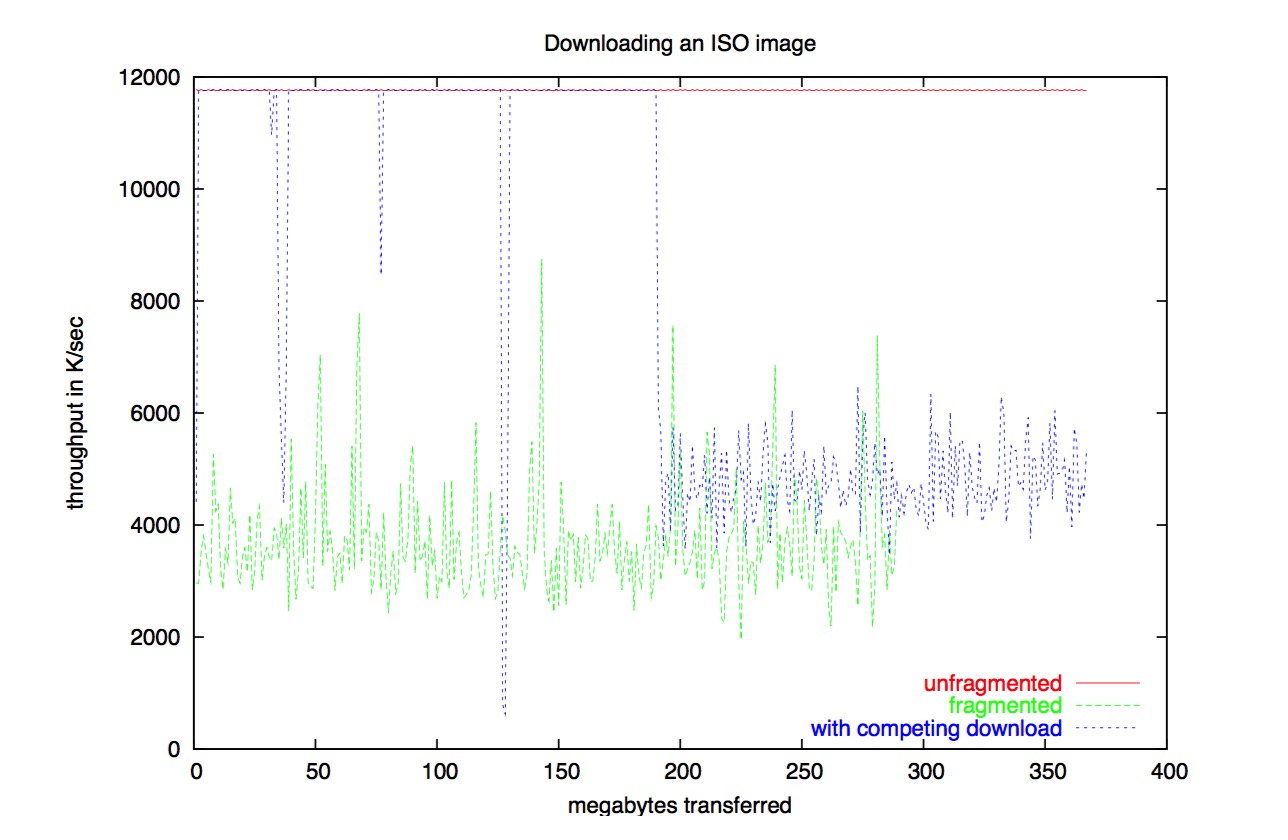
sendfile
sendfile() 和 write() 很像,只是可以直接从一个文件描述符到套接字,不需要 buffer 也不需要 read()。
这消除了从一个 buffer 缓存拷贝数据到用户空间的 buffer。
目前的网卡(所有的 gigabit 网卡)可以做 scatter-gather I/O。它可以从内核的 buffer 里面拿包头,而从 buffer 缓存里面直接拿包内容。(注:csum partial copy from user)
这结果叫做 TCP 0 拷贝。是终极目标。
Linux 和 FreeBSD 都有 sendfile,但有差异。
NetBSD 和 NetBSD 则没有。
内存映射I/O
除了读取文件,并在 buffer 中做一些只读的操作之外,还可以将文件映射到用户空间的内存中。
使用的系统调用是 mmap,这对可伸缩的网络 I/O 来说非常重要,因为它消除了 buffer。
OS 就能更好地使用从 buffer 缓存中节省下来的内存。
然而,为了达到正确的伸缩目的,维护页表是非常困难的。在 64 位机上更是如此。这里有一些图:
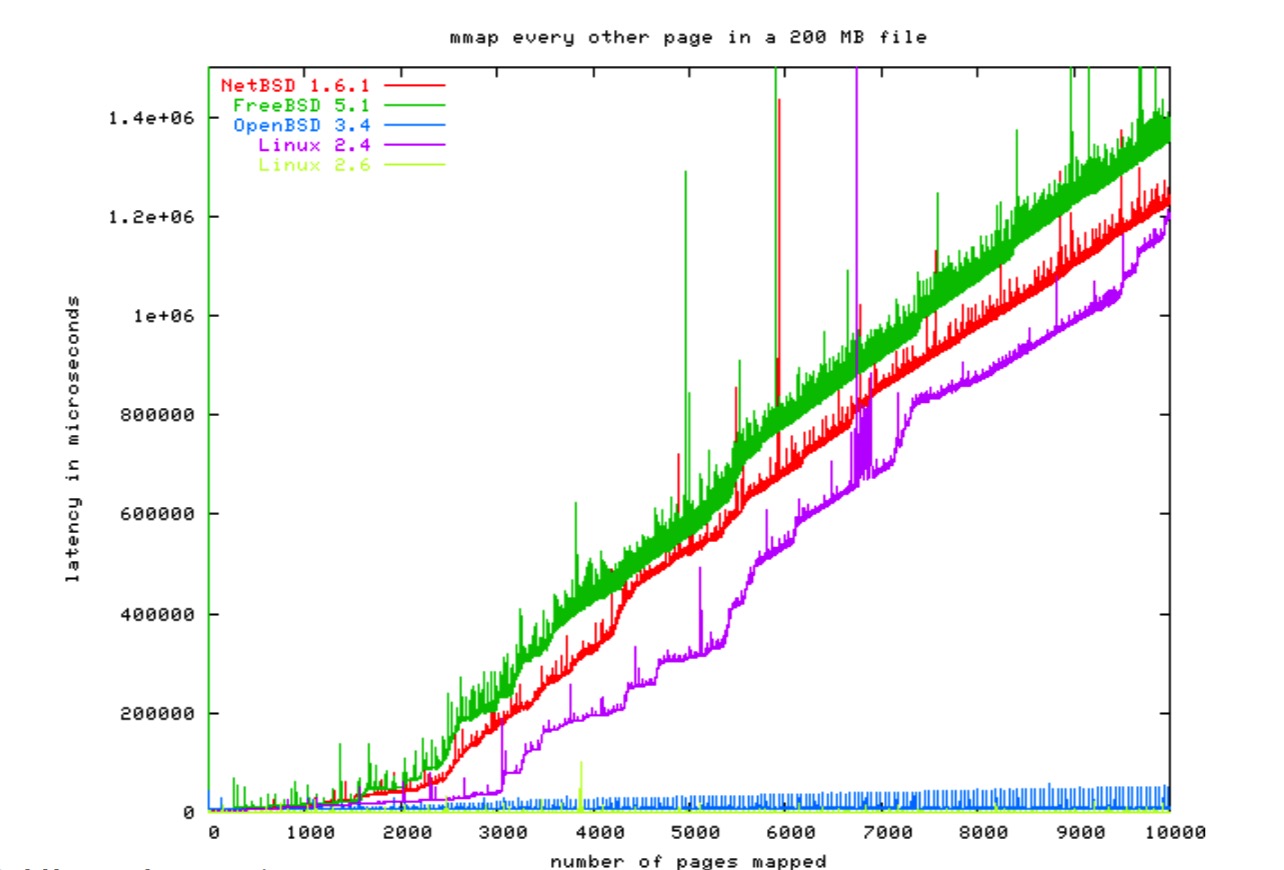
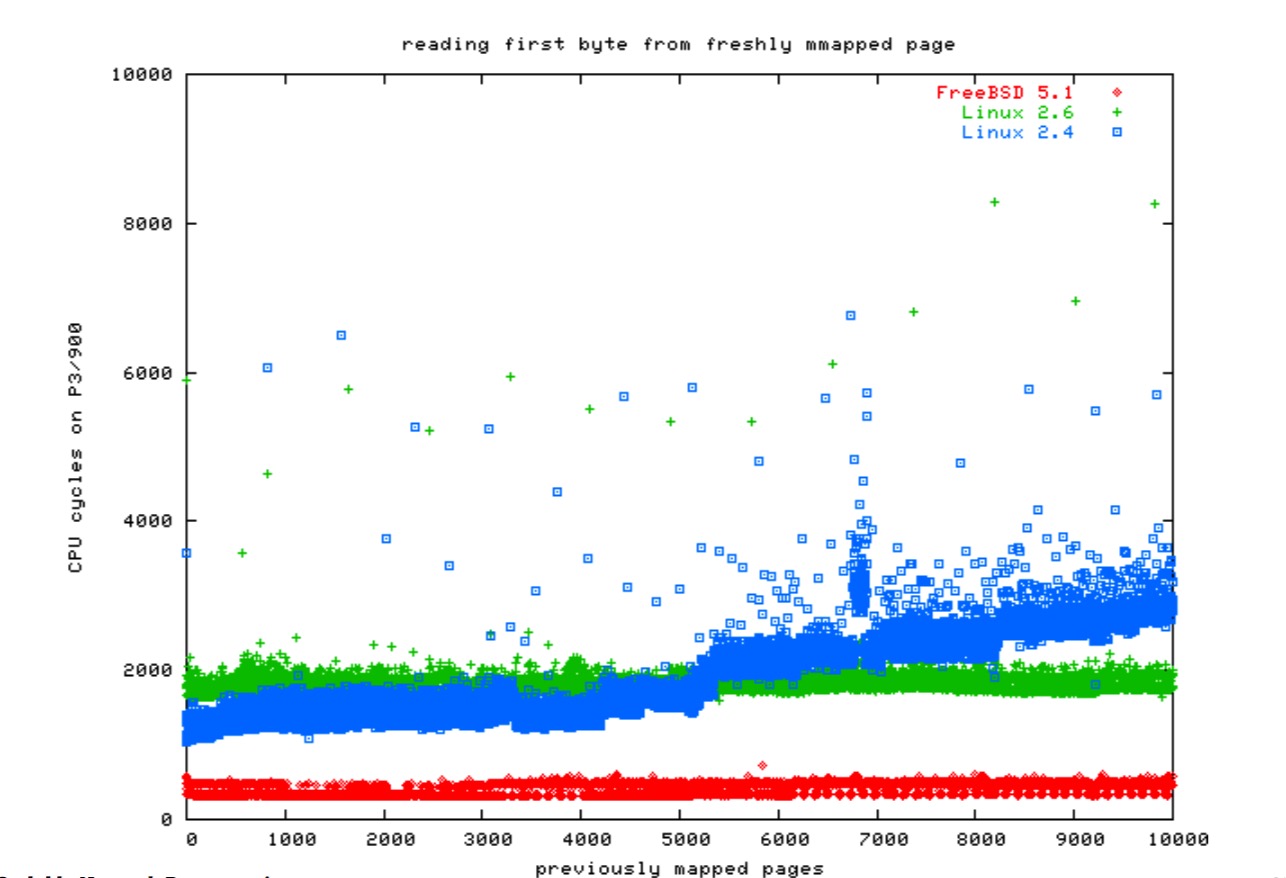
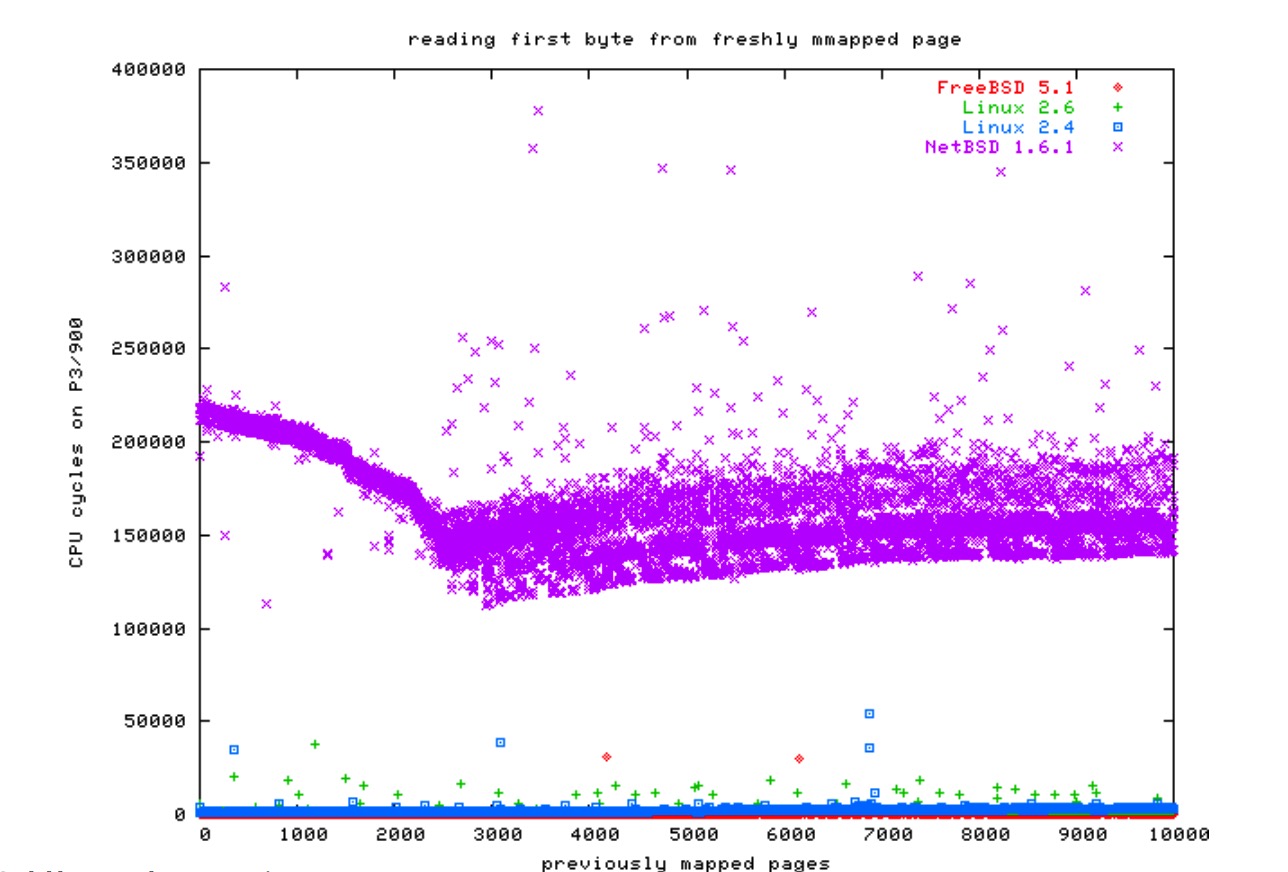

文件系统开销
如今这通常不再是个问题。但有一些病例。
我曾在局域网中运行了一个流量很大的 FTP 服务器。
有个人把他收藏的 JPEG 小黄图上传到了服务器。
在上传了 50000 张图片之后,我把他踢出去了。因为此时的服务器已经不堪重负了。
操作系统的内核几乎使用了 100% 的 CPU 一遍又一遍地遍历那个文件夹在内存中的文件列表。
如今我们有了像 XFS 和 reiserfs 的高级文件系统。ext3 和 FreeBSD 的 UFS 都支持文件夹 hash。
异步 I/O
POSIX 为异步 I/O 定了一套 API。不幸的是几乎没有操作系统实现了,如 Linux。
glibc 通过每个请求创建一个线程的方式来模拟。这糟糕到还不如一开始没有这个 API,因此没有人用。
这东西的本意是把读请求排队。之后你就可以向操作系统询问是否读完了。如果内核完成了就会给你发信号。
但问题是:当你收到信号时,你并不知道是队列中的哪个请求完成了。
异步 I/O 主要针对文件而不是套接字。如果你想使用 lseek 和 read 从一个 TB 级别的数据库读取 1000 个块,你可以让操作系统按指定顺序来读数据。这迫使硬盘磁头走指定的路径。
使用异步 I/O,系统就可以将块排序,以使硬盘磁头只用在整个硬盘上移动一次。按道理这很好,但实际这很糟糕。
例如,Solaris 有他们自己的异步 I/O API。也提供 POSIX API,但所有的调用都只返回 ENOSYS。
最重要的提供异步 I/O 的系统是 FreeBSD。
writev,TCP CORK 以及 TCP NOPUSH
一个 HTTP 服务器先向套接字写一个 HTTP 头,再写入文件内容。如果你使用 write(或者 sendfile),内核会先发送一个头部的 TCP 包,然后再发一个内容体的 TCP 包。
如果文件大小只有 100 字节大,就可以用一个包发出去。
很明显,这里可以使用一个 buffer 来解决:先将头部和内容拷贝到 buffer。但是我们想要 0 拷贝,不是吗?
有 4 种解决方案:writev,TCP_CORK(Linux),TCP_NOPUSH(BSD)以及 FreeBSD 的 sendfile。
writev
writev 很像批量写。你给他一个指针向量及长度,它会把它们都写出去。
除了对于 TCP 连接之外,和通常的写之间差异是很小的。
struct iovec x[2];
x[0].iov_base=header; x[0].iov_len=strlen(header);
x[1].iov_base=mapped_file; x[1].iov_len=file_size;
writev(sock,x,2); /* returns bytes written */
TCP CORK
int null=0, eins=1;
TCP CORK
/* put cork in bottle */
setsockopt(sock,IPPROTO_TCP,TCP_CORK,&eins,sizeof(eins));
write(sock,header,strlen(header));
write(sock,mapped_file,file_size);
/* pull cork out of bottle */
setsockopt(sock,IPPROTO_TCP,TCP_CORK,&null,sizeof(null));
BSD 的 TCP NOPUSH 也差不多,但你必须在写最后一次之前将该标志置空。这有点小尴尬。
FreeBSD 的 sendfile 就是 Linux 的 sendfile 加上了 writev 风格的向量处理头部,还有一个向量处理尾部。因此你不需要 TCP NOPUSH。
vfork
fork 在现代的类 Unix 操作系统上非常快,因此除了内存块没有其他实际的内存被拷贝。
然而,这还是相当的昂贵。尤其你在执行一个 CGI 程序的时候。这就是为什么 Linux 和 FreeBSD 又实现了传统的 vfork。
但 vfork 也不是处处都快。在 Linux 2.6 版本,如果你静态连接 dietlibc 库的话 vfork 就比 fork 要慢(250ms vs 180ms)。而如果是 glibc 的话,就是 250ms vs 320 ms 了。
那么哪个操作系统要好呢
我推荐 Linux 2.6。其各项基准在平衡在 O(1)。
FreeBSD 比较接近。除了 mmap 之外也都是 O(1)。
Linux 2.4 在 mmap 和大量进程的时候不行。使用 Linux 2.6 吧。
NetBSD 没有 kqueue 和 sendfile,只有 poll。然而,它依旧是一个高性能的操作系统。
我对 OpenBSD 很失望。磁盘性能烂透了,它甚至都不能在 Fast Ethernet 中维持一个 11MB/sec 的但文件下载。
从稳定角度来讲,Linux 和 NetBSD 一直都很稳定。FreeBSD 5.1-RELEASE 在负载过轻的时候会发生恐慌(FreeBSD 5.1-CURRENT 修复了)。OpenBSD 甚至在 3.4-CURRENT 版本都会挂掉或发生恐慌。OpenBSD 还惊倒我的是它如“/bsd: full”这样“有趣”的 syslog 信息。
下面有一些“大图”。是我在测试过程中遇到的惊人的结果:
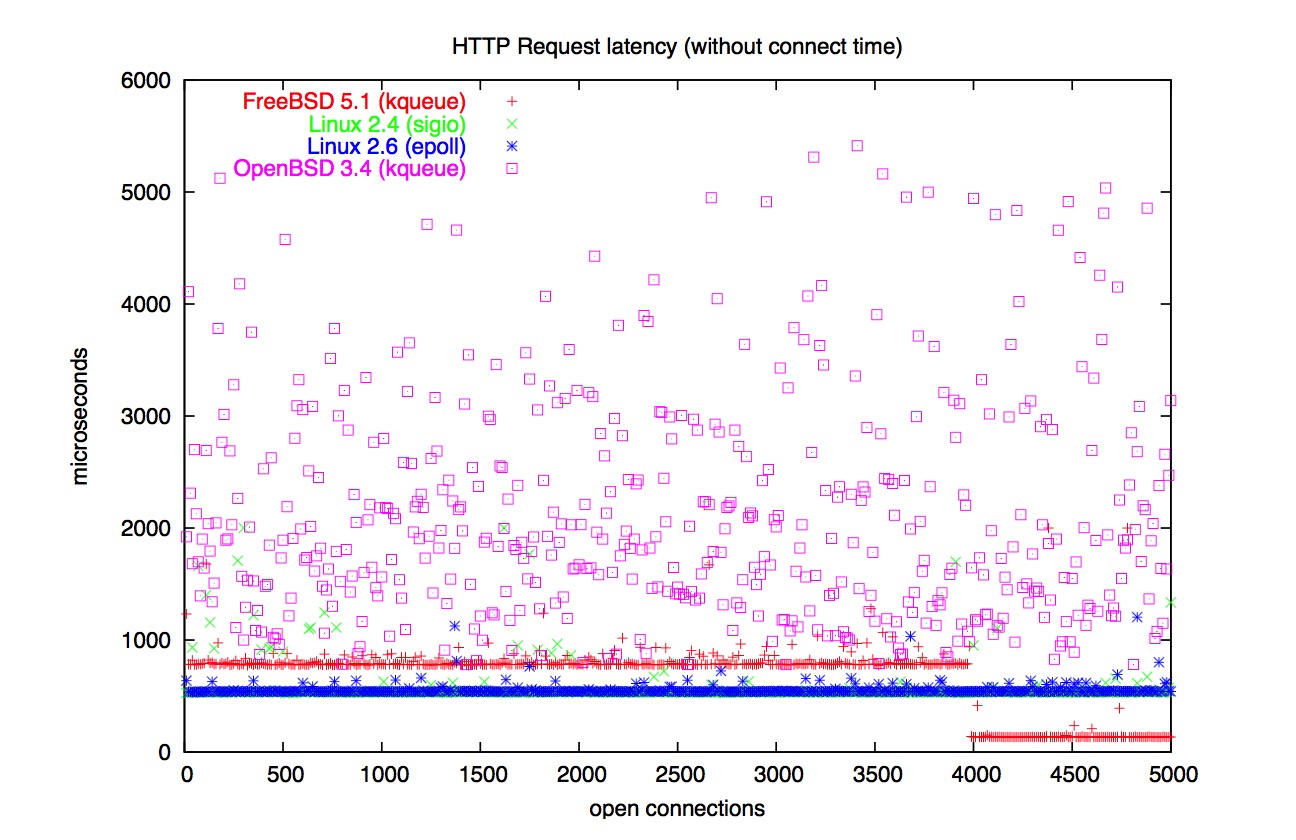
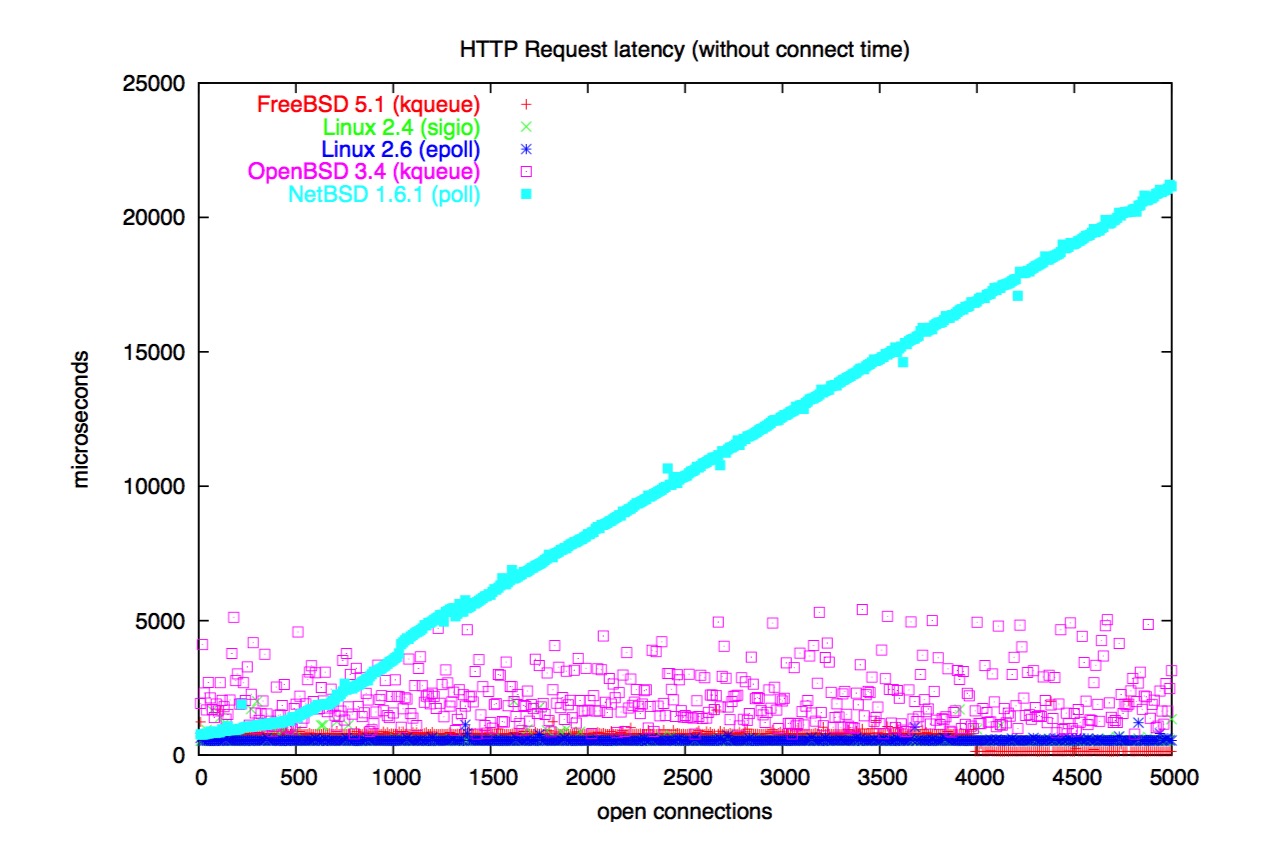
问题
感谢你们坐在这里听我啰嗦几个小时。
你们可以从这 2 个匿名的 cvs 来下载所有的基准测试代码:
% cvs -d:pserver:cvs@cvs.fefe.de:/cvs -z9 co libowfat
% cvs -d:pserver:cvs@cvs.fefe.de:/cvs -z9 co gatling
我的个人主页是 http://www.fefe.de/。
你可以给我发邮件 felix-linuxkongress@fefe.de
这本是一个演讲用的幻灯片,由于整理成文章,漏掉了一些信息,可以在原文档找到。原文档位于 bulk.fefe.de。
