
这篇是整个系列的实践文章。
整个系列的文章:
- Asynchronous programming. Blocking I/O and non-blocking I/O(翻译在 异步编程:阻塞 IO 和 非阻塞 IO)
- Asynchronous programming. Cooperative multitasking(翻译在 异步编程:协同多任务)
- Asynchronous programming. Await the Future(翻译在 异步编程:等待未来)
- Asynchronous programming. Python3.5+(翻译即本篇文章)
在这篇文章里,我们讨论一下迄今为止我们提到的概念在 Python 中的技术栈:从最简单的线程、进程到异步库。
最近,Python 中的异步编程变得越来越流行。Python 中有许多不同的库用于异步编程。其中一个库是 asyncio,它是 Python 3.4 中新加的 Python 标准库。在 Python 3.5 中,我们有了一个 async/await 语法。Asyncio 是异步编程在 Python 中越来越流行的部分原因。本文将解释异步编程是什么,并比较其中的一些库。
快速回顾
迄今我们在前面的文章中提到的概念有:
Python 代码现在分为两派:同步和异步。你应该将它们视为具有不同库和调用泛式的独立世界,但使用相通的变量和语法。
在已存在数十年的同步 Python 世界中,您可以直接调用函数,并且所有事情都按顺序处理,与编写代码完全相同。有一些方法可以并发运行代码。
同步世界
在这篇文章中,我们比较一下相同功能代码的不同实现。我们会试着执行 2 个函数。第一个是计算一个数的次幂:
def cpu_bound(a, b):
return a ** b
一共做 N 次:
def simple_1(N, a, b):
for i in range(N):
cpu_bound(a, b)
第二个是从互联网上下载数据:
def io_bound(urls):
data = []
for url in urls:
data.append(urlopen(url).read())
return data
def simple_2(N, urls):
for i in range(N):
io_bound(urls)
我们实现了简单的装饰器来比较函数的执行用时:
import time
from contextlib import ContextDecorator
class timeit(object):
def __call__(self, f):
@functools.wraps(f)
def decorated(*args, **kwds):
with self:
return f(*args, **kwds)
return decorated
def __enter__(self):
self.start_time = time.time()
def __exit__(self, *args, **kw):
elapsed = time.time() - self.start_time
print("{:.3} sec".format(elapsed))
现在我们把它们放在一起,然后运行,来看看你的机器执行这个代码用多长时间:
import time
import functools
from urllib.request import urlopen
from contextlib import ContextDecorator
class timeit(object):
def __call__(self, f):
@functools.wraps(f)
def decorated(*args, **kwds):
with self:
return f(*args, **kwds)
return decorated
def __enter__(self):
self.start_time = time.time()
def __exit__(self, *args, **kw):
elapsed = time.time() - self.start_time
print("{:.3} sec".format(elapsed))
def cpu_bound(a, b):
return a ** b
def io_bound(urls):
data = []
for url in urls:
data.append(urlopen(url).read())
return data
@timeit()
def simple_1(N, a, b):
for i in range(N):
cpu_bound(a, b)
@timeit()
def simple_2(N, urls):
for i in range(N):
io_bound(urls)
if __name__ == '__main__':
a = 7777
b = 200000
urls = [
"http://google.com",
"http://yahoo.com",
"http://linkedin.com",
"http://facebook.com"
]
simple_1(10, a, b)
simple_2(10, urls)
我们将同一函数顺序执行 N 次。
在我的机器上,CPU 密集函数耗时 2.18 秒,IO 密集函数耗时 31.4 秒。
我们得到了基本的表现。再来看看线程吧。
线程

线程是 OS 中最小的执行单元。进程的所有线程可以共享全局变量内存。如果一个全局变量被某个线程修改了,其他线程都能看到修改。
简单来说,线程是程序中的一系列操作,可以独立于其他代码执行。
线程是并发执行的,但也可以是并行的,这跟所运行的系统有关。
Python 的线程据我所知在所有的实现里(CPython, PyPy 和 Jython)都是使用的操作系统的线程。每一个 Python 线程都对应一个操作系统线程。
每单位时间在一个处理器核心上执行一个线程。该线程一直工作,直到消耗完它的时间片(默认为 100 毫秒)或直到它通过系统调用放弃对下一个线程的控制。
让我们使用线程实现我们的样例功能:
from threading import Thread
@timeit()
def threaded(n_threads, func, *args):
jobs = []
for i in range(n_threads):
thread = Thread(target=func, args=args)
jobs.append(thread)
# start the threads
for j in jobs:
j.start()
# ensure all of the threads have finished
for j in jobs:
j.join()
if __name__ == '__main__':
...
threaded(10, cpu_bound, a, b)
threaded(10, io_bound, urls)
在我的硬件上,CPU 密集函数耗时 2.47 秒,IO 密集函数耗时 7.9 秒。
IO 密集函数比之前快了 5 倍,这是因为我们用多个线程并行下载数据。但为什么 CPU 密集函数变慢了呢?
在 Python 的参考实现 CPython 中,存在一个臭名昭著的 GIL(全局解释器锁),我们在下一节慢慢展开。
全局解释器锁(GIL)
首先,GIL 是在对 Python 的任何访问之前都必须加的锁(不仅是 Python 代码的执行,还有调用 Python C API)。实质上,GIL 是一个全局信号量,它不允许多个线程在解释器中同时工作。
严格来讲,在使用未捕获的 GIL 运行解释器之后,唯一可用的调用是捕获 GIL。违反规则会导致立即崩溃(最好的选择)或延迟程序崩溃(更糟糕,更难调试)。
它如何工作的?
当线程启动时,它会捕获 GIL。过了一会儿,进程调度程序判定当前线程已经完成了足够的操作并将控制权交给下一个线程。线程#2 看到 GIL 被捕获,因此它不能继续工作,而是让自己陷入睡眠状态,把处理器让给线程#1。
但线程无法无限期地持有 GIL。在 Python 3.3 之前,GIL 每 100 个机器代码指令切换一次。在之后版本中,线程可以持有 GIL 不超过5毫秒。如果线程进行系统调用,使用磁盘或网络 IO 操作,也会释放 GIL。
事实上,Python 中的 GIL 使得在计算型问题(CPU 密集操作)中使用线程并行的想法毫无用处。它们甚至会在多处理器系统上顺序工作。在 CPU 密集的任务上,程序不会加速,只会减慢速度,因为现在线程必须将处理器时间减半。同时,GIL 的 IO 操作不会减慢,因为在系统调用之前,线程释放GIL。
很明显,由于创建线程、线程通信、捕获和释放信号量本身以及保留上下文的额外工作,GIL 减慢了我们程序的执行速度。但需要说明的是,GIL 并不限制并行执行。
GIL 不是语言的一部分,并不在所有语言实现中都有,而只存在于上面提到的 CPython 中。
那么为什么他还要存在呢?
GIL 可以保护操作数据结构时出现并发访问的问题。例如,它可以在对象的引用计数值更改时阻止竞争条件。GIL 可以很容易地集成非线程安全的 C 语言库。多亏了 GIL,我们才有了几乎所有的快速模块和绑定器。
例外情况是,C 库可以使用 GIL 控制机制。例如,NumPy 在长时间操作时会释放它。或者,当使用 numba 包时,开发者可以控制信号量来禁用自己。
在这个伤感的说明中,你可以得出结论,线程足以并行化与 IO 相关的任务。但计算任务应该在不同的进程中运行。
进程
从OS的角度来看,进程就是一种数据结构,它包含一个内存区域和一些其他资源,例如,由它打开的文件。通常,进程有一个主线程,但程序可以创建任意数量的线程。一开始,线程没有分配单独的资源,而是使用产生它的进程的内存和资源。因此,线程可以快速启动和停止。
多任务由调度器来处理,它是操作系统内核的一部分,会轮流将线程加载到处理器上去执行。
和线程类似,进程总是并发执行的,但也可以并行执行,这也取决于硬件功能。
from multiprocessing import Process
@timeit()
def multiprocessed(n_threads, func, *args):
processes = []
for i in range(n_threads):
p = Process(target=func, args=args)
processes.append(p)
# start the processes
for p in processes:
p.start()
# ensure all processes have finished execution
for p in processes:
p.join()
if __name__ == '__main__':
...
multiprocessed(10, cpu_bound, a, b)
multiprocessed(10, io_bound, urls)
在我的硬件上,CPU 密集函数耗时 1.12 秒,IO 密集函数耗时 7.22 秒。
因此,计算操作比线程实现执行得更快,因为现在我们并没有停留在捕获 GIL 上,但是 IO 密集函数花费的时间略多,因为进程比线程更重。
异步世界
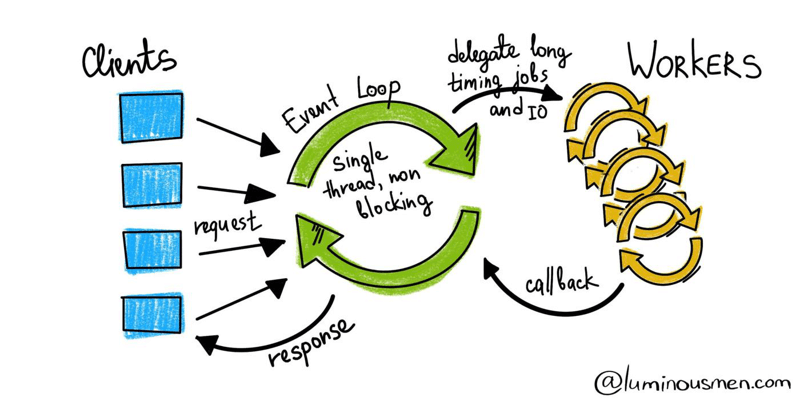
在异步世界中,一切都有所改变。一切都在一个中央事件处理循环中运行,这是一个允许你同时运行多个协程(一个重要的术语,简单来说它不是由 OS 管理的线程,除非它们是协作式多任务,因此不是真正的并行)的小块代码。协程同步工作,直到达到期望的结果,然后它停止,并将控制权转移给事件循环,还可能发生其他事情。
绿色线程

绿色线程是异步编程的原语级别的概念。绿色线程和常规线程一样,除了线程之间的切换是在应用程序代码(在用户层)完成,而不是在处理器(OS 层)中完成。它的核心是非阻塞操作。线程之间的切换仅在 IO 操作时发生。非 IO 线程会一直用控制权。
Gevent 是一个著名的 Python 库,用于使用绿色线程。Gevent 是一个绿色线程和非阻塞 IO。gevent.monkey 修改标准 Python 库的行为,以便它们允许执行非阻塞 IO 操作。
其他库:
让我们看看如果使用 gevent 库有什么性能改变:
import gevent.monkey
# patch any other imported module that has a blocking code in it
# to make it asynchronous.
gevent.monkey.patch_all()
@timeit()
def green_threaded(n_threads, func, *args):
jobs = []
for i in range(n_threads):
jobs.append(gevent.spawn(func, *args))
# ensure all jobs have finished execution
gevent.wait(jobs)
if __name__ == '__main__:
...
green_threaded(10, cpu_bound, a, b)
green_threaded(10, io_bound, urls)
结果是:CPU 密集函数耗时 2.23 秒,IO 密集函数耗时 6.85 秒。
CPU 密集函数更慢,IO 密集函数更快。和期望的一样。
Asyncio
asyncio 在 Python 文档中描述为 可以写出并行代码的 Python 库。然而,它既不是多线程,也不是多进程。不是同这两种技术实现的。
Gevent 和 Twisted 的目标是成为更高层次的框架,但 asyncio 旨在成为异步事件循环的低层次实现,其目的是将更高级别的框架(如Twisted,Gevent 或 Tornado)构建在其上。然而,就其本身而言,它本身就是一个合适的框架。
事实上,asyncio 是一个单线程、单进程项目:它使用协作多任务。asyncio 可以让我们编写 在同一个线程中运行的异步并发程序,使用事件循环来调度任务和 socket(和其他资源)的 多路 IO 复用。
asyncio 为我们提供了一个事件循环以及其他好东西。事件循环跟踪不同的 IO 事件并切换到准备好的任务并暂停等待 IO 的任务。因此,我们不会浪费时间在现在还没有准备好运行的任务上。
如何工作
异步函数和同步函数是不同的类型,你不能简单地混用。如果你要阻塞一个协程,你可以使用 time.sleep(10),而不是 await asyncio.sleep(10),你不把控制权返回给事件循环,整个进程都阻塞掉了。
您应该将您的代码库视为由同步代码或异步代码组成的:任何有 async def 的都是异步代码,其他的(包括 Python 文件或类的主体)都是同步代码。

这个想法非常简单。有一个事件循环。我们在 Python 中有一个使用 async def 声明的异步函数(协程),它改变了它的调用行为方式。特别是,调用它将立即返回一个协程对象,它基本上是“我可以运行协程并在你等待我时返回结果”。
我们将这些函数提供给事件循环并让它为我们运行它们。事件循环为我们提供了一个 Future 对象,它就像是一个我们将来会得到结果的承诺。我们坚信承诺,不时检查它是否有值(如果我们感到不耐烦的话),最后当这个对象有值时,我们会在其他一些操作中使用它。
当你调用 await 时,函数会在你要求等待的时候暂停,然后当它完成时,事件循环将再次唤醒函数并从 await 调用中恢复它,将任何结果传递出去。例如:
import asyncio
async def say(what, when):
await asyncio.sleep(when)
print(what)
loop = asyncio.get_event_loop()
loop.run_until_complete(say('hello world', 1))
loop.close()
在这个例子中,say() 函数会暂停并将控制权交还给事件循环,事件循环看到 sleep 需要运行,就调用它,然后调用 await 暂停它,并标记为一秒钟后恢复。一旦它恢复,say() 就完成了,并返回一个结果,然后让 main 准备再次运行,并且事件循环使用返回的值恢复它。
这就是异步代码可以同时发生这么多事情的方式 – 任何阻塞调用等待的东西,并被放到事件循环的暂停协程列表中,以便其他代码可以运行。暂停的所有代码都有一个相关的回调,回调会再次唤醒它 – 有些是基于时间的,有些是基于 IO 的,大多数都像上面的例子,等待来自另一个协程的结果。
让我们回到例子中。我们有两个阻塞函数 cpu_bound 和 io_bound。正如我所说,我们不能混用同步和异步操作 – 我们必须把它们全部变成异步。当然,并非所有功能都有异步库。一些代码仍然是阻塞的,必须让它以某种方式运行,以使它不会阻止我们的事件循环。为此,有一个很好的 run_in_executor() 方法,它会在内置线程池的一个线程中运行我们传递给它的代码,而不用阻塞事件循环主线程。我们将使用此功能来实现 CPU 密集函数。我们将完全重写 IO 密集函数以等待我们等待事件的那些时刻。
import asyncio
import aiohttp
async def async_func(N, func, *args):
coros = [func(*args) for _ in range(N)]
# run awaitable objects concurrently
await asyncio.gather(*coros)
async def a_cpu_bound(a, b):
result = await loop.run_in_executor(None, cpu_bound, a, b)
return result
async def a_io_bound(urls):
# create a coroutine function where we will download from individual url
async def download_coroutine(session, url):
async with session.get(url, timeout=10) as response:
await response.text()
# set an aiohttp session and download all our urls
async with aiohttp.ClientSession(loop=loop) as session:
for url in urls:
await download_coroutine(session, url)
if __name__ == '__main__':
...
loop = asyncio.get_event_loop()
with timeit():
loop.run_until_complete(async_func(10, a_cpu_bound, a, b))
with timeit():
loop.run_until_complete(async_func(10, a_io_bound, urls))
结果是:CPU 密集函数 2.23 秒,IO 密集函数 4.37 秒。
虽然 CPU 密集函数变慢了,但 IO 密集函数几乎是多线程的两倍。
做正确的选择
- CPU 密集 -> 多进程
- IO 密集,快速 IO,有限数量的连接 -> 多线程
- IO 密集,慢速 IO,较多连接 -> asyncio
总结
如果是一个不依赖于外部服务的典型 Web 应用程序,并且响应时间可预测较短的相对有限数量的用户,则线程将更简单。
如果应用程序花费大部分时间读/写数据而不是处理数据,则 async 是合适的。例如,您有很多慢速请求 – websockets,长轮询或外部同步后端缓慢,请求结束时未知。
同步编程最经常用于开始应用开发,命令都是顺序执行。
即使使用条件分支,循环和函数调用,我们也会考虑一次执行一个步骤的代码。完成当前步骤后,进入下一步。
异步应用的行为不同。它仍然一次运行一步,但区别在于系统一直向前推进,它不等待当前执行步骤的完成。因此,我们要进行事件驱动的编程。
asyncio 是一个很棒的库,很酷,它被包含在 Python 标准库中。asyncio 已经开始为应用程序开发构建一个生态系统(aiohttp,asyncpg 等)。还有其他事件循环实现(uvloop,dabeaz/curio,python-trio/trio),我认为 asyncio 将在更强大的工具中发展。
链接
- PEP 342
- PEP 492
- 看看以前的关于 asyncio 的 演示文稿
- Robert Smallshire 的有趣的演讲 “Get to grips with asyncio in Python 3”
- David Beazley’s Curio library
- Trio project
- David Beazley 关于摆脱 asyncio 的演讲
- uvloop - faster event-loop for asyncio
- Some thoughts on asynchronous API design in a post-async/await world
本篇文章翻译自 luminousmen 的关于异步编程的系列文章,原文地址在文章开头列出。
