这篇整个 异步编程 系列文章的第三篇。整个系列要回答一个简单问题:什么是异步编程?
起初当我开始深入研究这个问题的时候,我以为我知道它是什么。但事实证明,我并不知道。好了,让我们了解一下吧。
整个系列的文章:
- Asynchronous programming. Blocking I/O and non-blocking I/O(翻译在 异步编程:阻塞 IO 和 非阻塞 IO)
- Asynchronous programming. Cooperative multitasking(翻译在 异步编程:协同多任务)
- Asynchronous programming. Await the Future(翻译即本篇文章)
- Asynchronous programming. Python3.5+(翻译在 异步编程:Python3.5)
一些应用使用多进程而不是多线程来实现并行(第一篇文章)。虽然在编程细节上不太一样,但在本文从概念上将他们视为同一模型,在我说线程的时候,你可以轻松地把它理解成进程。
此外,这里我只会谈到简单明了的协作多任务 回调。因为它在异步框架实现中非常常见且广泛使用。
现代应用最常见的活动是处理输入输出,而不是捣弄数字。问题是输入输出函数是阻塞的。实际向磁盘写或者从网络上读跟 CPU 的速度比 是相当长的时间。函数在任务完成之间都不会结束,因此,你的应用此时啥都做不了。对于需要高性能的应用,这就成了最大的障碍,因为其他活动和 IO 操作都在等待。
一个标准的解决方案是使用线程。每个阻塞的 IO 操作都用一个单独的线程。当函数陷入阻塞时,处理器可以调度其它需要 CPU 的线程运行。
在这篇文章里,我们大体上谈谈同步和异步的概念。
同步
在这个概念中,一个线程被分配给一个单独的任务,并开始处理这个任务。当任务完成时,线程拿到下一个任务,继续处理:它一个接一个地执行所有命令以完成一个指定的任务。在这个系统中,线程不能把一个任务丢到半路上去处理下一个任务。由此我们可以确保:无论何时何地当一个函数执行时,在执行其他任务(这个任务可能会修改当前运行任务的数据)之前,它不能被挂起,且会被完全完成。
单线程
如果该系统在单线程上执行,且有多个任务与之关联,那这些任务会一个接一个地顺序执行。

如果任务总是按照确定的顺序执行,则后续任务的实现可以假设所有早期任务都已完成且没有错误,所有输出都可供使用 – 逻辑明确简化。
如果一个命令很慢,那么整个系统都要等待这个命令完成,没有其他办法了。
多线程
在多线程系统中,原则得以保留:一个线程被分配给一个任务,并开始处理这个任务直到任务完成。
但在这个系统中,每个任务在不同的线程中执行。线程由操作系统管理,多个线程可能在有多个处理器或者多个核的系统上并行运行,也可能在单处理器系统上交错运行。
现在我们有多个线程和任务(不是同一种任务,而是几种不同的任务)可以并行执行。通常,任务在处理的时间上有所不同,而实际上线程在完成一个任务之后才能去执行下一个。

多线程程序更复杂,一般也更容易出错,主要问题有:竞争条件,死锁,资源匮乏等。
异步
一种方法一种风格,异步就是 非阻塞泛式。异步算是并发编程的一种泛式,但它不是并行的(译注:翻译在 并发与并行之不同)。
大多数现代操作系统提供事件通知机制。例如,一个在一个 socket 上的 read 调用将会阻塞,直到发送方真正发送了一些数据。应用可以请求操作系统监控这个 socket,并将事件通知放到队列里。应用可以在它方便时检查事件()并获取数据。被称为异步是因为应用在某点想要某一数据,但拿到数据是在另一点(可能是时间或者空间上的点)。它是非阻塞的,是因为应用线程是空闲的,可以做其他事情。

异步代码从主应用程序线程中删除 阻塞 操作,以便继续执行,但稍后(或可能在其他地方)执行,并且处理程序可以更进一步。简单地说,主线程设置任务并将其执行转移到一段时间(或另一个独立的线程)。
异步和上下文切换
虽然异步编程可以防止所有这些问题,但它实际上是针对一个完全不同的问题而设计的:CPU 上下文切换。当你运行多个线程时,每个 CPU 核心仍然只能一次运行一个线程。为了允许所有线程/进程共享资源,CPU经常切换上下文。为了精简,CPU 以随机间隔保存线程的所有上下文信息并切换到另一个线程。CPU 会以非确定的间隔在您的线程之间不断切换。线程也是资源,它们不是免费的。
异步编程本质上是使用用户空间线程的协作多任务,其中应用程序管理线程和上下文切换,而不是CPU。基本上,在异步世界中,仅在定义的切换点而不是在非确定性间隔中切换上下文。
对比
和同步模型相比,异步模型在以下情景下工作更好:
- 有大量任务,因此可能始终至少有一个任务可以在执行
- 任务有大量的 IO 操作,导致同步程序浪费大量时间阻塞,而这些时间可以用与执行其他任务
- 这些任务在很大程度上是彼此独立的,因此不需要任务间通信(任务间通信会造成一个任务等待其他任务)
这些条件几乎完美地表征了一个 CS 架构环境中典型的繁忙服务器(如 Web 服务器)。每个任务以接收请求和发送回复的形式表示一个使用 IO 的客户端请求。服务器实现是异步模型的主要饯行者,这就是为什么 Twisted 和 Node.js 以及其他异步服务器库近年来如此受欢迎。
为什么不使用更多线程?如果一个线程在 IO 操作上阻塞,另一个线程可以继续执行,对吗?但是,随着线程数量的增加,您的服务器可能会开始遇到性能问题。对于每个新线程,都存在与线程状态的创建和维护相关联的一些内存开销。异步模型的另一个性能增益是它避免了上下文切换 – 每次操作系统将控制权从一个线程转移到另一个线程时,它必须保存所有相关的寄存器,内存映射,堆栈指针,CPU上下文等,以便线程可以从中断处继续执行。这样做的开销可能非常大。
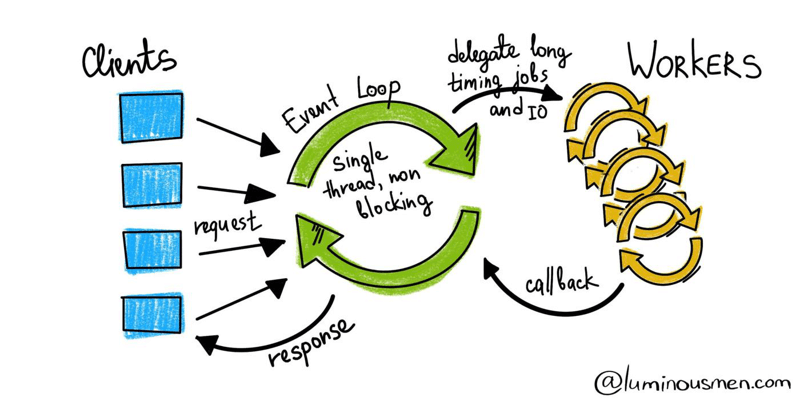
事件循环
如果执行线程忙于处理另一个任务,新任务到达的事件如何到达应用程序?事实是操作系统有许多线程,实际与用户交互的代码与我们的应用程序分开执行,只向它发送消息。
那如何管理所有的事件线程呢?在事件循环里。

事件循环就和它的名字一样,有一个事件队列(这里存放所有发生的事件,在上图中叫做任务队列)和一个循环不停地将这些事件从队列中拉出来并在事件上执行回调(所有执行都在调用堆栈上进行)。API 表示异步函数调用的 API,例如等待来自客户端或数据库的响应。
因此,所有操作首先进入调用堆栈,而异步命令进入 API,完成后需要回调进入任务队列,然后再次调用堆栈执行。
此过程的协作发生在事件循环中。
你看,这与我们上一篇文章中谈到的反应堆模式有什么不同?对,没什么不同。
当事件循环形成程序的中央控制流结构时,如通常那样,它可以被称为主循环或主事件循环。这种叫法很合适,因为此类事件循环是应用程序内的最高控制级别。
在事件驱动编程中,应用程序表示对某些事件的兴趣,并在它们发生时对它们做出响应。从操作系统收集事件或监视其他事件源的责任由事件循环处理,用户可以注册在事件发生时调用的回调。事件循环通常会一直运行。
| JS 的事件循环解释:[What the heck is the event loop anyway? | Philip Roberts | JSConf EU](https://youtu.be/8aGhZQkoFbQ) |
总结
总结一下整个理论系列:
- 应用程序中的异步操作可以使其更高效,最重要的是对用户来说更快
- 节省资源。操作系统线程比进程廉价,但每个任务使用一个线程仍然非常昂贵。重用它会更有效 - 这就是异步编程为我们提供的。如果能够重用线程会更有效率,这就是异步编程提供给我们的东西
- 这是优化和扩展 IO 密集应用的最重要技术之一(是的,对于 CPU 密集型应用就没什么用了)
- 异步编程对开发者来说非常难以编写和调试
本篇文章翻译自 luminousmen 的关于异步编程的系列文章,原文地址在文章开头列出。
